Spenderanalyse mit KI - Teil II
Lesedauer: 7 Minuten
In dieser zweiteiligen Fallstudie begleiten wir die fiktive Non-Profit-Organisation Zero Hunger e.V. auf ihrer Reise hin zu einer datengetriebenen Organisation. Im ersten Teil haben wir aufgezeigt, wie der fiktive Verein eine hausweite Datenstrategie inklusive Tracking-Konzept und KPI-Framework einführt. Diese Datenstrategie ist der Startpunkt für den nächsten Schritt von Zero Hunger: Spenderprognosen mithilfe von Künstlicher Intelligenz ermitteln. Mithilfe von Technologien des Machine Learnings (ML) sollen Prognosen über das Verhalten von Spenderinnen und Spendern getroffen werden. Diese sollen die Basis bilden für eine Kampagne zur Gewinnung von neuen Dauerspendern. Wie das gelingen kann, beschreiben wir in diesem Teil der fiktiven Fallstudie.
Künstliche Intelligenz im Fundraising
So genannte Spenderprognosen (Predictive Analytics) sind nur eine Einsatzmöglichkeit von KI-getriebenen Technologien im Fundraising. Insbesondere im Online-Marketing können Large Language Modelle (LLM) wie ChatGPT hilfreiche Unterstützung bieten, z.B. bei der Recherche von passenden SEO-Keywords, beim Texten von Anzeigen und von Landingpages für Spendenkampagnen oder auch bei der Beantwortung von Fragen im Spenderservice.
Mindset und Organisationskultur
Damit Technologien Künstlicher Intelligenz im Fundraising eingesetzt werden können, braucht es eine Führungskultur in der NGO, die datenbasierte Entscheidungen trifft und KI als Chance für die Organisation versteht. Durch den Aufbau einer Datenstrategie hat es Zero Hunger geschafft, dieses Mindset im Verein Stück für Stück aufzubauen. Mitarbeitende und Führungskräfte begegnen digitalen Themen mit Offenheit. Entscheidungen werden nicht aus persönlichen Erfahrungen heraus getroffen, sondern auf der Basis von Datenanalysen. Es herrscht Einigkeit, dass gegenüber dem Spender transparent kommuniziert wird, wie seine Daten gespeichert und verarbeitet werden. Daten werden DSGVO-konform gesammelt, die Auswahl von passenden KI-Tools findet unter ethischen Gesichtspunkten statt.
Spendervorhersagen treffen mithilfe von Predictive Analytics
Eines der größten Potentiale von Künstlicher Intelligenz im Fundraising liegt in der Prognose von Spenderverhalten. Darauf basierend können auf den Spender zugeschnittene Fundraisingaktivitäten geplant und umgesetzt werden. Solche prädikativen Analysen (predictive analytics) erkennen Muster, Trends und Verbindungen innerhalb vorhandener Spenderdaten. Somit können Vorhersagen darüber getroffen werden, wie hoch die Erfolgswahrscheinlichkeit einer Spendenkampagne bei einem konkreten Spendersegment ist. Um Spenderprognosen mittels Künstlicher Intelligenz erstellen zu können benötigt es einen möglichst großen Input an Spenderdaten mit verschiedenen Parametern. Dieser kann beispielsweise aus einem Data Warehouse stammen. Algorithmen des Machine Learnings werden darauf optimiert, Korrelationen in den Eingabedaten zu erkennen und Vorhersagen zu treffen.
Zielsetzung
Um die Zielgruppe der Dauerspender zu verstehen, lohnt sich ein Blick auf den Spender-Funnel. So könnte der Funnel für diese fiktive Fallstudie aussehen:
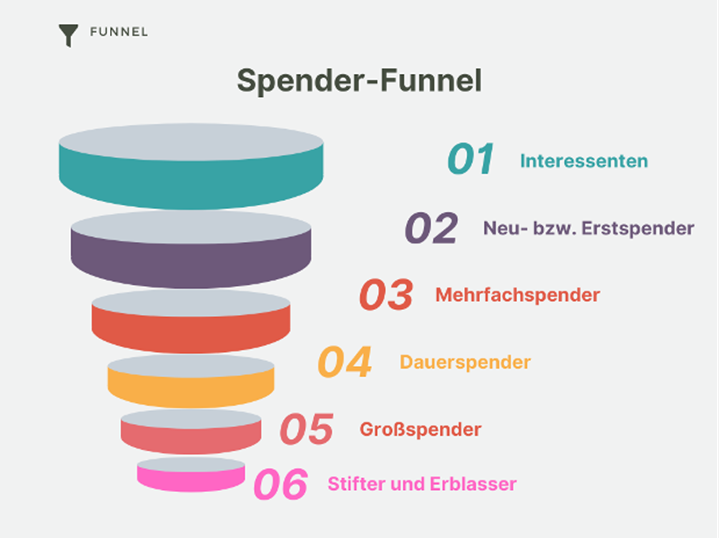
Der Funnel beschreibt die verschiedenen Schritte der Spenderbindung und -entwicklung. Je höher die Stufe, desto engagierter und wertvoller ist der Spender. Zero Hunger hat das Ziel, den Anteil der Dauerspender innerhalb der nächsten drei Jahren zu verdoppeln. Das heißt, Zero Hunger muss in dieser Zeit möglichst viele Mehrfachspender in Dauerspender überführen.
Dementsprechend definiert Zero Hunger folgende Zielsetzung für die prädikative Analyse mittels Machine Learning:
Identifiziere mir unter den Neu- und Mehrfachspendern alle Spender, die das Potential haben, Dauerspender zu werden.
Diese Spender werden von Zero Hunger mit einer crossmedialen Dauerspender-Kampagne bespielt. Die Kampagne besteht aus einem Print-Mailing, verzahnt mit einer Kampagnen-Landingpage auf der Website von Zero Hunger. Im Vergleich zu Kampagnen ohne vorherige prädikative Analyse minimiert Zero Hunger bei dieser Kampagne die Streuverluste, die es in der Regel bei jeder Spendenkampagne gibt. Es werden gezielt nur die Personen angeschrieben, die laut ML-Modell am nächsten an das Profil eines Dauerspenders heranreichen. Dadurch wird die Conversion-Rate optimiert und der ROI gesteigert.
Exkurs: Beispieltraining
Um das Verfahren von Predictive Analytics mithilfe von Machine Learning zu erklären, haben wir für diesen Blog-Beitrag einen Trainingsdatensatz aus dem E-Commerce-Bereich genutzt und ein entsprechendes Modell auf diesen Daten trainiert. Die gesamte Dokumentation des Trainings kann hier nachgelesen werden:
Im Folgenden fassen wir die wichtigsten Schritte zusammen. Das Training besteht aus vier Schritten, die einen Zyklus bilden:
- Explore and Adapt: man schaut sich verschiedene Eigenschaften des Datensatzes an, und versucht die Zusammenhänge zwischen den Daten genauer zu verstehen. Dann passt man das Modell bzw. den Datensatz an die Erkenntnisse an.
- Train: das Modell trainieren
- Evaluate: die Performance anhand von Daten messen, die zuvor nicht im Training verwendet wurden
- Inference/Go-Live: Verwendung des Modells im Echtbetrieb
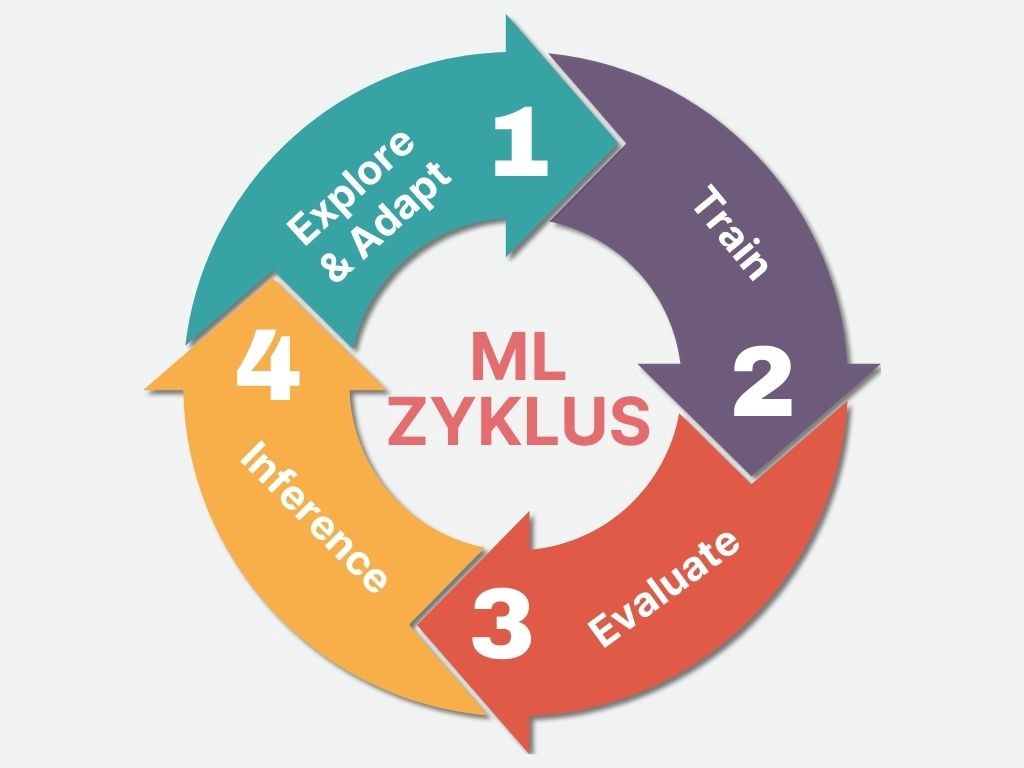
Schritt 1: Explore and Adapt
Zunächst wird der Datensatz hinsichtlich seiner Eigenschaften analysiert. Der Datensatz ist ein Test-Datensatz von der Plattform Kaggle, einer von Google betriebenen Online-Community für Datenwissenschaftler. Der Datensatz ist auf Kaggle populär, aber er stammt aus dem Bereich des E-Commerce. Die Grundzüge des Vorgehens lassen sich aber auch auf NGO übertragen.
Wir beschränken uns in diesem Beispiel-Training auf eine einfache Frage: Welcher Kunde erzielte in den letzten zwei Jahren mehr und welcher weniger als 1.000 € Umsatz. Übertragen auf das Szenario von Zero Hunger wären die Kunden mit mehr als 1.000 € Umsatz die potenziellen Dauerspender, die mit einer Kampagne aktiviert werden sollen. Die Spender unter 1.000 € Umsatz fallen als Zielgruppe der Dauerspender-Kampagne heraus. Die Wahrscheinlichkeit, dass diese Spender konvertieren, ist zu gering.
Unser Test-Datensatz hat 2.240 Zeilen (Kunden) mit insgesamt 29 Spalten/Dimensionen. Die Dimensionen beschreiben den Kunden. Es handelt sich beispielsweise um demografische Daten (z.B. ‚Year_Birth‘), Einkommen (‚Income‘), Angaben zum Familienstatus (‚Marital_Status), Abschluss (‚Education‘) usw. Da die Testdaten aus dem E-Commerce-Bereich stammen, sind auch Dimensionen aufgeführt, die für den NGO-Bereich nicht relevant sind.
| ID | Year_Birth | Education | Marital_Status | Income | Kidhome | Teenhome | Dt_Customer | Recency | MntWines | MntFruits | MntMeatProducts | MntFishProducts | MntSweetProducts | MntGoldProds | NumDealsPurchases | NumWebPurchases | NumCatalogPurchases | NumStorePurchases | NumWebVisitsMonth | AcceptedCmp3 | AcceptedCmp4 | AcceptedCmp5 | AcceptedCmp1 | AcceptedCmp2 | Complain | Z_CostContact | Z_Revenue | Response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5524 | 1957 | Graduation | Single | 58138.0 | 0 | 0 | 04-09-2012 | 58 | 635 | 88 | 546 | 172 | 88 | 88 | 3 | 8 | 10 | 4 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 1 |
| 1 | 2174 | 1954 | Graduation | Single | 46344.0 | 1 | 1 | 08-03-2014 | 38 | 11 | 1 | 6 | 2 | 1 | 6 | 2 | 1 | 1 | 2 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2 | 4141 | 1965 | Graduation | Together | 71613.0 | 0 | 0 | 21-08-2013 | 26 | 426 | 49 | 127 | 111 | 21 | 42 | 1 | 8 | 2 | 10 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 3 | 6182 | 1984 | Graduation | Together | 26646.0 | 1 | 0 | 10-02-2014 | 26 | 11 | 4 | 20 | 10 | 3 | 5 | 2 | 2 | 0 | 4 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 4 | 5324 | 1981 | PhD | Married | 58293.0 | 1 | 0 | 19-01-2014 | 94 | 173 | 43 | 118 | 46 | 27 | 15 | 5 | 5 | 3 | 6 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2235 | 10870 | 1967 | Graduation | Married | 61223.0 | 0 | 1 | 13-06-2013 | 46 | 709 | 43 | 182 | 42 | 118 | 247 | 2 | 9 | 3 | 4 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2236 | 4001 | 1946 | PhD | Together | 64014.0 | 2 | 1 | 10-06-2014 | 56 | 406 | 0 | 30 | 0 | 0 | 8 | 7 | 8 | 2 | 5 | 7 | 0 | 0 | 0 | 1 | 0 | 0 | 3 | 11 | 0 |
| 2237 | 7270 | 1981 | Graduation | Divorced | 56981.0 | 0 | 0 | 25-01-2014 | 91 | 908 | 48 | 217 | 32 | 12 | 24 | 1 | 2 | 3 | 13 | 6 | 0 | 1 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2238 | 8235 | 1956 | Master | Together | 69245.0 | 0 | 1 | 24-01-2014 | 8 | 428 | 30 | 214 | 80 | 30 | 61 | 2 | 6 | 5 | 10 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2239 | 9405 | 1954 | PhD | Married | 52869.0 | 1 | 1 | 15-10-2012 | 40 | 84 | 3 | 61 | 2 | 1 | 21 | 3 | 3 | 1 | 4 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 1 |
Bezogen auf das Szenario von Zero Hunger käme dieser Datensatz aus dem Data Warehouse. Durch die sauber aufgesetzte Datenstrategie hat der Verein Zugriff auf qualitativ hochwertige Spenderdaten und eine sauber strukturierte, breite Datenbasis, die als Input für das Machine Learning Modell dient. Die Spenderdatensätze können dadurch einfach per CSV-/JSON-Export aus dem Data Warehouse exportiert und für das Training verwendet werden.
Ziel des Trainings ist es, die Kunden in zwei Gruppen aufzuteilen:
- Kunden, die mehr als 1.000 € Umsatz generieren: 1.000 +
- In unserem Szenario sind dies die potenziellen Dauerspender, d.h. die Zielgruppe der Dauerspender-Kampagne
- Kunden, die weniger als 1.000 € Umsatz generieren: 0-999
- In unserem Szenario sind dies alle anderen Einzel- und Mehrfachspender
Diese Kundengruppen werden später als die beiden Ziele/Labels des Trainings dienen. Das Modell soll lernen, die Kundengruppe (1.000 + oder 0-999) vorherzusagen. Für das Training des Modells auf diese beiden Kundengruppen werden nur 7 der ursprünglichen 29 Dimensionen genutzt, und zwar die 7, die den meisten Aufschluss über die gesuchten Kundengruppen geben. Dies haben wir durch mehrere Versuche mit unterschiedlichen Kombinationen und den beiden Visualisierungsverfahren (t-SNE und PCA) herausgefunden.
Visualisierung des Datensatzes mit der t-SNE Methode
Bei dieser Methode der Daten-Visualisierung werden die 7-Dimensionen der Eingabetabelle auf zwei Dimensionen reduziert. Diese 2D-Repräsentation kann man in einem Graphen darstellen:
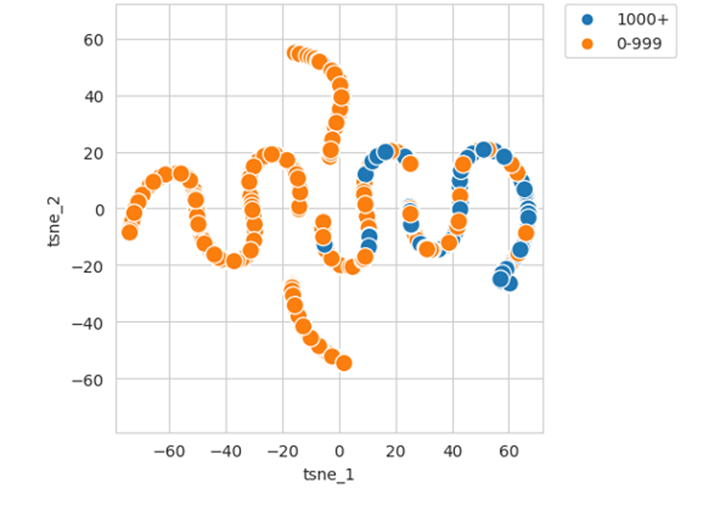
In der Grafik sieht man, dass es zwar eine Überlappung zwischen beiden Gruppen gibt, sich eine Vielzahl von orangenen (0-999) Kunden aber tatsächlich auf der linken Bildhälfte befindet und die blauen 1000+-Kunden auf der rechten Seite Platz finden. Das legt nahe, dass es tatsächlich möglich sein wird, anhand der o.g. Eingabedaten die beiden Kundengruppen zu unterscheiden. Neben der t-SNE-Methode wurde in der Explore-Phase eine weitere Visualisierungsmethode angewendet: PCA. Auch diese Methode zeigt, dass die beiden gewünschten Kundengruppen voneinander unterscheidbar sind.
Schritt 2: Das Training
Da die Visualisierungen eine Unterscheidung der Eingabedaten anhand der ausgewählten 7 Dimensionen erlauben, kann man nun mit dem Training beginnen.
Das Training wird für 50 Epochen durchgeführt. Dies sind Teilschritte des Trainings. In jeder Epoche wird der Trainingsdatensatz einmal ins Modell gegeben. Dabei wird der Fehler zwischen erwartetem und tatsächlichem Label (0,1) bestimmt. Anschließend wird das Netzwerk optimiert, sodass die Fehlerwahrscheinlichkeit abnimmt.
Bevor wir mit dem Training beginnen, muss jedoch der Datensatz in 3 Teile eingeteilt werden. Die Aufteilung wird automatisiert und zufällig vorgenommen. Der überwiegende Anteil der Daten (z.B. 75%) ist im Trainingsdatensatz und wird für die Optimierung des Modells verwendet. Zwei weitere Teile (z.B. jeweils 12,5%) werden zur Evaluation der Genauigkeit (sog. Accuracy) außerhalb der Optimierung verwendet.
Schritt 3: Die Evaluation
Nach dem Durchlaufen aller Epochen kommen die Testdaten ins Spiel. Mit diesem Datensatz werden weitere Evaluationen am Ende des Trainings durchgeführt. Passt das trainierte Modell gut zu den Testdaten, sagt das Modell mit einer hohen Genauigkeit voraus, welcher Kunde voraussichtlich mehr als 1.000 € Umsatz generiert und welcher weniger.
In unserem Beispiel-Training kommen wir auf eine Genauigkeit von 87,87 %. Das bedeutet, wenn 100 Kunden in das Netzwerk geladen werden, liegt das Netzwerk bei knapp 88% mit der Einschätzung richtig. Die Genauigkeit je Kundengruppe ergibt Folgendes:
- Wenn das Netzwerk den Wert 0-999 vorhersagt, liegt es in 90% der Fälle richtig
- Wenn das Netzwerk den Wert 1000+ vorhersagt, liegt es in 77% der Fälle richtig
Die unterschiedliche Genauigkeit könnte damit zu erklären sein, dass im Trainingsdatensatz wesentlich mehr Kunden mit einem Umsatz zwischen 0-999 € enthalten waren.
Schritt 4: Der Einsatz des Modells
Nachdem wir die Performance anhand von Daten gemessen haben, die zuvor nicht im Training verwendet wurden, und die Genauigkeit zufriedenstellend ist, können wir das Modell nun im Echtbetrieb einsetzen.
Wir haben zwei fiktive Kunden und müssen für diese folgende 7 Parameter kennen: Age, Income, Education, Marital_Status, Kidhome, Teenhome, Dt_Customer_Years
Unsere fiktiven Kunden sind:
Margret Musterfrau
- Alter: 56
- Jahreseinkommen: 100000
- Bildungsniveau: Phd
- Familienstand: Married
- Anzahl der Teenager im Haushalt: 2
- Anzahl der Kinder im Haushalt: 0
- Kunde seit: 3
Max Mustermann
- Alter: 28
- Jahreseinkommen: 25000
- Bildungsniveau: Graduated
- Familienstand: Divorced
- Anzahl der Teenager im Haushalt: 0
- Anzahl der Kinder im Haushalt: 3
- Kunde seit: 2
Gibt man diese fiktiven Kunden ins Modell erhält man folgendes Ergebnis des Trainings:
- Margret: 1000+
- Max: 0-999
Übertragen auf das Szenario von Zero Hunger kann die NGO aus dieser prädikativen Analyse den Schluss ziehen, dass Margret Musterfrau in jedem Fall zu den Adressaten der Dauerspender-Kampagne zählt. Die Erfolgschancen, dass Margret auf die Kampagne konvertiert, sind laut Modell sehr hoch. Max Mustermann hingegen kann bei der Kampagne vernachlässigt werden, da die Wahrscheinlichkeit, ihn in einen Dauerspender zu überführen, laut Modell sehr gering ist.
Erfolgsmessung
Mithilfe des KPI-Frameworks, das Zero Hunger für die Dauerspender Kampagne aufgesetzt hat, kann der Erfolg der Kampagne gemessen werden. Diese Erfolgsmessung ist zugleich auch der Gradmesser für die Güte des Machine Learning Modells. Ziel ist es, durch die vorherige KI-basierte Spenderanalyse die Responserate des Dauerspendermailings im Vergleich zu Mailings ohne vorherige Analyse zu erhöhen, den Return on Invest zu steigern sowie die durchschnittlichen Kosten pro Dauerspender zu senken. Mittel- bis langfristig soll durch eine erfolgreiche Spenderansprache die Spenderloyalität insgesamt gesteigert werden. Die Daten aus dem KPI-Framework fließen schlussendlich wieder zurück in das Machine Learning Modell. Dadurch wird das Modell fortlaufend trainiert und die Spenderprognose weiter optimiert.
Fazit
Diese fiktive Case Study von Zero Hunger zeigt die Entwicklung eines gemeinnützigen Vereins mit geringem Reifegradlevel hin zu einer datengetriebenen Organisation, die mithilfe von KI-basierten Spenderprognosen die Effektivität ihrer Fundraising-Kampagnen erheblich steigert.
Durch das Beispiel-Training mit einem E-Commerce-Datensatz konnten wir die grundlegenden Schritte der prädikativen Analyse mittels Machine Learning beschreiben. Die Einteilung von Kunden in Klassen mit einem Umsatz über und unter 1.000 EUR spiegelt die Unterscheidung zwischen möglichen Dauerspendern und weniger langfristig engagierten Unterstützern wider. Diese Anpassung auf den gemeinnützigen Sektor zeigt das enorme Anwendungspotential, das KI-basierte Spenderprognosen im Fundraising bieten.
Non-Profit-Organisationen können mithilfe von Machine Learning ihre Spenderdaten analysieren, um potenzielle Dauerspender zu identifizieren. Dieser Ansatz erlaubt es den NGOs, ihre Ressourcen gezielt einzusetzen, um jene Unterstützer anzusprechen, die das größte Potential haben, langfristige Bindungen einzugehen.
Unsere Empfehlung an NGOs ist daher klar: Es lohnt sich, die Schätze in den eigenen Spenderdaten mithilfe von KI zu heben. Eine organisationsweise Datenstrategie und eine nachhaltige Datenkultur bieten dafür ein stabiles Fundament.
Die Fallstudie wurde zusammen mit dem IT-Büdchen erarbeitet. Das IT-Büdchen unterstützt insbesondere NGO dabei, Kampagnen zu gestalten, zu kommunizieren, zu steuern und zu messen.