
Google Consent Mode V2 und der Datenschutz
Google Consent Mode V2 und der Datenschutz
Lesedauer: 10 Minuten
Einführung in den Consent Mode V2
In der Ära der digitalen Transformation sehen sich Unternehmen mit dem komplexen Spannungsfeld zwischen dem Schutz von Nutzerdaten und der Notwendigkeit, datengesteuerte Entscheidungen zu treffen, konfrontiert. Mit der Einführung des Consent Mode V2 reagiert Google auf eine sich wandelnde rechtliche und gesellschaftliche Landschaft, in der Datenschutz und -sicherheit zunehmend in den Vordergrund rücken. Angesichts verschärfter Datenschutzverordnungen wie der DSGVO und dem Digital Markets Act (DMA), sowie einer wachsenden Sensibilität der Nutzer für ihre Online-Privatsphäre, musste Google mit dem Consent Mode V2 reagieren, damit Unternehmen den Spagat zwischen Compliance und effektiver Datennutzung meistern können.
Warum führt Google den Consent Mode V2 ein?
Google verspricht, dass Unternehmen durch die Implementierung des Consent Mode V2 ihre Compliance-Strategien verbessern können, indem sie den Nutzern mehr Kontrolle über die Verwendung ihrer Daten geben. Dies stärkt nicht nur das Vertrauen der Nutzer in die Produkte, sondern ermöglicht es den Unternehmen auch, innerhalb der gesetzlichen Grenzen zu operieren und gleichzeitig wertvolle Daten für die Optimierung ihrer Online-Präsenz zu sammeln.
Die Implementierung des Consent Mode V2 erfordert technisches Know-how und ein tiefgreifendes Verständnis der geltenden Datenschutzgesetze. Unternehmen müssen sicherstellen, dass ihre Nutzung des Consent Mode V2 mit den Erwartungen und Rechten der Nutzer übereinstimmt und gleichzeitig den gesetzlichen Anforderungen gerecht wird. Die Notwendigkeit einer fortlaufenden Überprüfung und Anpassung der Datenschutzpraktiken bleibt also bestehen, um mit den sich ständig weiterentwickelnden Standards Schritt zu halten.
In der herkömmlichen Tracking-Praxis ist das Erfassen von Nutzerdaten direkt abhängig von der sofortigen Zustimmung beim Website-Besuch. Dieses binäre Modell – Zustimmung führt zu Tracking, keine Zustimmung führt zu keinem Tracking – bietet zwar eine direkte Einhaltung von Datenschutzvorschriften wie der DSGVO, ist jedoch in seiner Anpassungsfähigkeit und im Umgang mit nicht-einwilligenden Nutzern begrenzt. In der aktuellen digitalen Landschaft verzichten immer mehr Nutzer auf den Consent, was zu einer signifikanten Lücke in den Datensätzen der Unternehmen führt. Wenn Nutzer die Datenerfassung ablehnen und dadurch 30% des Traffics nicht erfasst werden, können die daraus resultierenden Analysen und Optimierungsstrategien stark verzerrt und ungenau sein. Der Consent Mode V2 wurde entwickelt, um genau diese Lücke im digitalen Marketing und der Datenanalyse zu schließen.
Die Funktionsweise des Consent Mode V2
Der Consent Mode V2 ist in zwei Hauptmodi unterteilt: den Basic Mode und den Advanced Mode. Diese bieten unterschiedliche Ebenen der Datenerfassung und -verarbeitung, je nachdem, welche Zustimmung der Nutzer erteilt hat.
Funktionsweise Basic Mode
Im Basic Mode des Consent Mode V2 werden Daten in einer Weise erfasst, die die Privatsphäre des Nutzers respektiert, indem keine personenbezogenen Daten oder identifizierbaren Informationen gesammelt werden. Aber wie funktioniert das genau, und was bedeutet das für Unternehmen und Nutzer?
Wenn ein Nutzer die Verwendung von Cookies ablehnt, werden keine Daten erhoben. Für die Conversion-Modellierung in Google Ads & Analytics wird dann ein allgemeines Modell verwendet. In diesem Modus verwendet Google eine Technik namens „Cookieless-Pings“, die es ermöglichen soll, Interaktionen zu messen, ohne Nutzer über Websites hinweg zu verfolgen. Es werden grundlegende Informationen wie die Art der Conversion-Aktion, die Tageszeit oder der Browsertyp erfasst, jedoch ohne Verbindung zu einer eindeutigen Nutzer-ID. Dies kann ohne Network-Calls erfasst werden.
Für den Nutzer bedeutet dies, dass seine Interaktionen auf der Website in einer aggregierten Form erfasst werden. Es gibt keine personalisierte Datenspeicherung oder -analyse, und die Daten können nicht dazu verwendet werden, individuelle Profile zu erstellen oder personalisierte Werbung zu schalten. Unternehmen erhalten durch den Basic Mode wertvolle aggregierte Einblicke in das Nutzerverhalten, die für allgemeine Website-Optimierungen genutzt werden können. Auch wenn die Daten nicht für personalisierte Marketingstrategien geeignet sind, bieten sie doch eine solide Basis für die Verbesserung der Benutzererfahrung und die allgemeine Leistung der Website oder einer Kampagne.
Funktionsweise Advanced Mode
Der Advanced Mode des Consent Mode V2 tritt in Kraft, wenn Nutzer ihre Zustimmung zur Verwendung von Cookies und ähnlichen Technologien geben. Dieser Modus ermöglicht eine weit umfangreichere Datenerfassung und -verarbeitung.
Im Advanced Mode werden personenbezogene Daten wie Cookie-IDs oder gegebenenfalls andere identifizierende Informationen genutzt, um detaillierte Einblicke in das Nutzerverhalten zu gewinnen. Diese Daten ermöglichen es, individuelle Nutzerpfade zu verfolgen, Nutzerinteressen zu analysieren und personalisierte Marketingkampagnen zu entwickeln. In diesem Modus verwendet Google fortschrittliche Algorithmen, um Daten zu erfassen und zu verarbeiten, wodurch Unternehmen nicht nur verstehen können, wie Nutzer mit ihrer Website interagieren, sondern auch, wie sie ihre Optimierungsmaßnahmen an die Bedürfnisse und Präferenzen der Nutzer anpassen können.
Für den Nutzer bedeutet die Zustimmung im Advanced Mode, dass seine Daten genutzt werden können, um ihm eine personalisierte Online-Erfahrung zu bieten. Dies kann personalisierte Inhalte, zielgerichtete Werbung oder Empfehlungen umfassen, basierend auf seinem bisherigen Online-Verhalten. Für Unternehmen bietet der Advanced Mode tiefe Einblicke in das Nutzerverhalten und ermöglicht präzises Targeting und Personalisierung. Mit diesen Informationen können Unternehmen ihre Marketingstrategien feinjustieren, die Konversionsraten verbessern und letztlich die Wirkung ihrer Online-Marketing-Maßnahmen maximieren.
Der Consent Mode V2 kann als Schritt gesehen werden, um ein Gleichgewicht zwischen dem Respektieren der Nutzerpräferenzen und dem Bedarf an detaillierten Daten für die Geschäftsoptimierung zu finden. Durch die Wahl zwischen Basic Mode und Advanced Mode können Unternehmen ihre Datenstrategien flexibel an die Zustimmung ihrer Nutzer anpassen, wodurch sie sowohl den Datenschutzanforderungen gerecht werden als auch wertvolle Einblicke für ihre Geschäftsentscheidungen gewinnen.
Cookieless Pings & Datenmodellierung
Im Rahmen des Google Consent Mode V2 sind Cookieless Pings eine zentrale Innovation, die es ermöglicht, Nutzerinteraktionen zu erfassen, selbst wenn traditionelle Cookies nicht eingesetzt werden können. Diese Technologie ist entscheidend für die Datenerfassung in einem zunehmend restriktiven Cookie-Umfeld.
Technische Funktionsweise von Cookieless Pings
Cookieless Pings sind HTTP-Requests, die von einer Webseite gesendet werden, um bestimmte Interaktionen oder Ereignisse zu melden, ohne dabei auf herkömmliche Browser-Cookies angewiesen zu sein. Diese Pings werden ausgelöst, um Interaktionsdaten direkt an Server zu übermitteln, auch wenn der Nutzer die Speicherung von Cookies abgelehnt hat oder der Browser die Cookie-Verwendung einschränkt.
Für Nutzer bieten Cookieless Pings einen erhöhten Datenschutz. Ihre Interaktionen auf der Webseite tragen zur Verbesserung von Diensten und zur Nutzererfahrung bei, ohne dass ihr Online-Verhalten über längere Zeiträume oder über verschiedene Webseites hinweg nachverfolgt wird. Nur bei einer korrekten Implementierung des Consent Modes stellt dieser sicher, dass die Privatsphäre gewahrt bleibt, während Nutzer weiterhin von einer funktionierenden und reaktionsfähigen Webseite profitieren. Cookieless Pings im Consent Mode V2 können eine zukunftsorientierte Lösung für die Datenerfassung sein, die sowohl den wachsenden Datenschutzbedürfnissen der Nutzer als auch den analytischen Anforderungen der Unternehmen gerecht wird. Durch diese Technologie können Unternehmen weiterhin wertvolle Daten sammeln und analysieren, auch in einer Landschaft, die zunehmend von Datenschutzregulierungen und technologischen Einschränkungen geprägt ist.
Diese Methode kann das Risiko von Datenschutzverletzungen verringern, da individuell identifizierbare Informationen nicht erfasst werden. Jedoch bewegt sich diese Technologie in einer gewissen Grauzone bezüglich der DSGVO-Konformität, da die Anonymisierung und die damit verbundene Datenverarbeitung noch immer Gegenstand von Diskussionen und rechtlichen Überprüfungen sind.
Google Consent Mode V2 = Cookieless-Tracking?
Der Google Consent Mode V2 und das Cookieless-Tracking sind beides Antworten auf die wachsenden Datenschutzbedenken und die technologischen Veränderungen in der digitalen Welt. Obwohl sie Ähnlichkeiten aufweisen, dienen sie unterschiedlichen Zwecken und funktionieren auf unterschiedliche Weisen. In diesem Kapitel werden wir die Beziehung zwischen dem Google Consent Mode V2 und dem Cookieless-Tracking untersuchen, um zu verstehen, wie sie sich ergänzen und worin ihre Unterschiede bestehen.
Sowohl der Google Consent Mode V2 als auch das Tracking ohne Cookies stellen Lösungen dar, um in einer zunehmend cookie-aversen Online-Welt Daten zu erfassen. Sie zielen darauf ab, Einblicke in das Nutzerverhalten zu gewähren, ohne auf traditionelle, oft als invasiv empfundene Tracking-Methoden angewiesen zu sein. Beide Ansätze ermöglichen es, Daten zu sammeln und auszuwerten, selbst wenn Nutzer dem Setzen von Cookies nicht zustimmen.
Während Cookieless-Tracking gänzlich ohne Cookies auskommt und Daten auf alternative Weisen erfasst, bietet der Consent Mode V2 eine flexible Struktur, die sich an die Zustimmung der Nutzer anpasst. Im Basic Mode des Consent Mode V2 werden ähnlich wie beim Cookie-losen Tracking Daten ohne die Verwendung personenbezogener Cookies gesammelt. Der Advanced Mode hingegen ermöglicht eine detailliertere Datensammlung, wenn Nutzer ihre Zustimmung geben, und geht damit über das Konzept des Trackings ohne Cookies hinaus.
Der Consent Mode V2 kann als eine Erweiterung oder ein komplementäres System zum Cookieless-Tracking betrachtet werden. Er integriert die Flexibilität, sowohl mit als auch ohne Cookies zu arbeiten, abhängig von der Nutzerzustimmung. Dieser Ansatz reflektiert die Realität, dass nicht alle Nutzer Tracking vollständig ablehnen; einige sind bereit, ihre Daten für eine bessere Online-Erfahrung zu teilen, solange sie die Kontrolle behalten.
Kritische Betrachtung der DSGVO-Konformität
Es ist wichtig zu betonen, dass sowohl der Consent Mode V2 als auch das Cookie-lose Tracking unter die Bestimmungen der DSGVO fallen. Die Einhaltung der DSGVO hängt nicht nur davon ab, ob Cookies verwendet werden, sondern auch davon, wie Nutzerdaten erfasst, verarbeitet und gespeichert werden. Transparente Kommunikation, die Einholung von Zustimmung und die Gewährleistung der Datensicherheit sind unerlässlich, um den Anforderungen der DSGVO gerecht zu werden.
Der Google Consent Mode V2 bietet einen Ansatz, der das Beste aus beiden Welten zusammenbringen soll: die Flexibilität des Cookieless-Trackings und die Möglichkeit, mit Zustimmung detailliertere Daten zu erfassen. Diese hybride Herangehensweise ermöglicht es Unternehmen, datengesteuerte Entscheidungen innerhalb des rechtlichen Rahmens zu treffen und gleichzeitig die Präferenzen ihrer Nutzer zu respektieren. Durch das Verständnis und die Anwendung dieser Technologien können Unternehmen ihre Analysefähigkeiten in einer sich ständig verändernden digitalen Landschaft verbessern, ohne die Vertrauensbasis mit ihren Nutzern zu untergraben.
Unternehmen sollten diese Technologien nicht als einseitige Lösungen betrachten, sondern als Teil eines größeren Datenschutz- und Datenanalyse-Ökosystems. Die Auswahl und Implementierung dieser Technologien sollte stets von einer gründlichen Bewertung der Datenschutzpraktiken und -ziele des Unternehmens begleitet werden. Eine transparente Kommunikation mit den Nutzern über die verwendeten Tracking-Methoden und der Schutz ihrer Daten sollte im Mittelpunkt jeder digitalen Strategie stehen.
Die Einführung des Consent Mode V2 ist ein wesentlicher Schritt für Unternehmen, um in der heutigen datengetriebenen und datenschutzbewussten Welt erfolgreich zu sein. Während der erste Teil dieses Artikels die technischen und strategischen Aspekte des Consent Mode V2 beleuchtet hat, ist es unerlässlich, den Datenschutz als integralen Bestandteil der Implementierung zu betrachten. In den nächsten Kapiteln dieses Artikels werden wir uns eingehend mit den Datenschutzaspekten einer erfolgreichen Implementierung befassen.
Datenschutzrechtliche Grundlagen
Die digitale Landschaft unterliegt einem ständigen Wandel, insbesondere im Hinblick auf Datenschutz und Regulierung der “Big Player” der Werbeindustrie. Mit Inkrafttreten des Digital Markets Act (DMA) mit 6. März 2024 in der Europäischen Union und der zunehmenden Macht von Unternehmen wie Google, welche als Gatekeeper im DMA definiert wurden, entstehen neue Herausforderungen und Anforderungen im Bereich des Datenschutzes. Diese Anforderungen betreffen auch Webseitenbetreiber direkt, da Google diese an sie weitergegeben hat.
Die Einholung der Einwilligung zur Verarbeitung personenbezogener Daten zu Zwecken von Marketing und Personalisierung ist eine grundlegende Anforderung der Datenschutzgrundverordnung (DSGVO) der Europäischen Union. Aus diesem Grund sind Webseite- und App-Betreiber verpflichtet, klare und transparente Einwilligungen von ihren Nutzern einzuholen.
Zusätzlich zur DSGVO unterliegen bestimmte Datenverarbeitungen im digitalen Raum weiteren Datenschutzgesetzen, die sicherstellen sollen, dass die Privatsphäre der Nutzer respektiert wird. Für Deutschland gilt etwa zusätzlich das Telekommunikations-Datenschutzgesetz (TTDSG), in Österreich das Telekommunikationsgesetz (TKG). Diese beiden Gesetze enthalten auch Regelungen zur Einwilligung der Nutzer im Rahmen von lokalen Speicherungen von Informationen auf Endgeräten.
Der Digital Market Act
Der Digital Market Act (DMA, zu deutsch “Gesetz über digitale Märkte”) ist ein Gesetz der Europäischen Union, das darauf abzielt, die Marktstellung großer digitaler Plattformen (sog. Gatekeeper) zu regulieren und faire Wettbewerbsbedingungen zu schaffen. Im Kontext Datenschutz legt der DMA auch Richtlinien fest, die die Verarbeitung personenbezogener Daten zu Werbezwecken betreffen. Eine der betroffenen Plattformen des DMA ist Google, das wiederum seine Verpflichtungen direkt an die Betreiber von Webseiten und Apps weitergibt. Dafür wurde der Google Consent Mode V2 entwickelt.
Anforderungen von Google
Die Richtlinie zur Einwilligung der Nutzer in der EU von Google legt fest, dass Webseitenbetreiber und Nutzer von Google-Diensten sicherstellen müssen, dass Endnutzer im Europäischen Wirtschaftsraum (EWR) bestimmte Informationen erhalten und ihre Einwilligung zur Verarbeitung ihrer Daten geben.
Nach der Richtlinie sind die Betreiber verpflichtet:
“Sie sind verpflichtet, eine rechtswirksame Einwilligung dieser Endnutzer für folgende Aktivitäten einzuholen:
- den Einsatz von Cookies oder anderer Formen der lokalen Speicherung von Informationen, soweit die Einholung einer Einwilligung hierfür gesetzlich vorgeschrieben ist; und
- die Erhebung, Weitergabe und Nutzung von personenbezogenen Daten zur Personalisierung von Werbeanzeigen.
Wenn Sie die Einwilligung einholen, sind Sie verpflichtet:
- Aufzeichnungen über die von den Endnutzern abgegebenen Einwilligungen aufzubewahren; und
- den Endnutzern eine klare Anleitung bereitzustellen, wie diese die Einwilligung widerrufen können.”
Die Nichteinhaltung der Richtlinie zur Einwilligung der Nutzer in der EU von Google kann dazu führen, dass Google die Nutzung des betreffenden Dienstes einschränkt, sperrt oder die Vereinbarung mit dem Nutzer kündigt. Dies führt für eine Vielzahl der Unternehmen zu erheblichen Risiken und potenziellen Umsatzeinbußen.
Konkrete Maßnahmen aufgrund des Google Consent Mode V2
Der Google Consent Mode V2 betrifft alle Werbetreibenden, die Google Ads für personalisierte Werbung nutzen und das Tracking mittels Google Analytics durchführen. Wenn auf einer Webseite Google-Dienste wie Google Analytics, Google Ads Pixel, Google Tag Manager oder Google Ads eingesetzt werden und Daten von Nutzern aus dem Europäischen Wirtschaftsraum (EWR) erfasst werden, führt kein Weg am Google Consent Mode V2 herum.
Es ist wichtig zu beachten, dass Google eine wirksame Einwilligung der betroffenen Personen nicht nur bei der Datenerhebung auf Webseiten einfordert, sondern auch dann, wenn Daten in Google-Marketing-Tools hochgeladen werden, die aus Offline-Quellen (zum Beispiel Offline-Conversions oder Daten zu Ladenverkäufen), aus Apps oder aus Programmen stammen, die nicht von Google stammen.
Der Google Consent Mode V2 muss dann genutzt werden, wenn die Funktionen Messung, personalisierte Anzeige und Remarketing genutzt werden.
Weiters ist es entscheidend zu verstehen, dass der Google Consent Mode V2 keine Ersatzlösung für Consent Management Plattformen (CMP) ist, sondern lediglich eine Schnittstelle zu Google darstellt. Diese Schnittstelle überträgt die getroffenen Cookie- und Datenschutzeinstellungen, die im CMP auf der jeweiligen Webseite festgelegt wurden, an die konkret eingesetzten Google-Dienste.
Durch den Google Consent Mode V2 hat sich also nicht die Einwilligung nach der DSGVO bzw. dem TTDSG/TKG verändert, diese gelten weiterhin uneingeschränkt und parallel weiter. Vielmehr kommt es durch den Google Consent Mode V2 zu einer Datenübermittlung an Google, damit Google weiß, ob und welche Dienste der Betroffenen verknüpft werden dürfen.
Folgen der Nicht-Einwilligung durch den Nutzer
Falls die Einwilligung durch die Webseitenbesucher verweigert wird, speichern die ausgelösten Tags keine Cookies. Stattdessen werden Informationen zur Nutzeraktivität gesendet. Diese Informationen sowie der Einwilligungsstatus werden über verschiedene Arten von Pings ohne Cookies oder Signale an den Google-Server gesendet:
- Pings zum Einwilligungsstatus für Google Ads- und Floodlight-Tags übermitteln den standardmäßigen Einwilligungsstatus und aktualisieren diesen, wenn der Besucher die Einwilligung erteilt oder verweigert.
- Conversion-Pings signalisieren eine durchgeführte Conversion.
- Google Analytics-Pings werden von allen Seiten einer Webseite gesendet, auf denen Google Analytics implementiert ist und Ereignisse protokolliert werden.
Diese Pings können funktionsbezogene Informationen wie Zeitstempel, Nutzer-Agent und Referrer-URL sowie zusammengefasste, nicht personenidentifizierbare Informationen wie Hinweise auf Anzeigenklicks, Einwilligungsstatus und zufällige Zahlen umfassen. Zudem können Informationen zur Plattform zur Einwilligungsverwaltung des Webseiteninhabers enthalten sein.
Kompatibilität der Consent-Management-Plattform
Die Kompatibilität der Consent-Management-Plattform mit dem Google Consent Mode V2 ist von entscheidender Bedeutung, um einerseits die Google Richtlinie zu erfüllen und andererseits die Vorgaben der DSGVO einzuhalten.
Eine effektive CMP-Lösung muss nahtlos mit dem Google Consent Mode V2 zusammenarbeiten, um die Einwilligung der Nutzer zur Verarbeitung ihrer Daten zu verwalten. Dabei ist es wichtig, dass die CMP die erforderlichen Funktionen und Integrationen bereitstellt, um den Consent Mode ordnungsgemäß zu implementieren und die Zustimmungsstatus der Nutzer in Echtzeit zu verfolgen. Google stellt eine Übersicht über jene CMP vor, welche den Google Consent Mode V2 bereits integriert haben.
Anpassung Datenschutzhinweise
In den Datenschutzhinweise auf der Webseite muss zusätzlich zum CMP eine transparente Information über die gewählte Variante im Google Consent Mode V2 erfolgen, um die Betroffenen den Anforderungen des Art. 13 DSGVO entsprechend zu informieren. Hintergrund davon ist, dass die DSGVO Transparenzpflichten vorsieht.
Aktuell ist es notwendig, die Datenschutzhinweise zu prüfen und anzupassen, um die Anforderungen vollumfänglich zu erfüllen.
Zusammenfassung
Eine fehlerhafte Implementierungen der Technologie kann die Datenqualität verschlechtern und so die Aussagekraft der eigenen Analysen verfälschen. Im schlimmsten Falle können Verstöße gegen die Richtlinien von Google und insbesondere gegen die DSGVO schwerwiegende Konsequenzen für Unternehmen mit sich bringen. Im Fall von Google-Richtlinien können Verstöße dazu führen, dass das betroffene Unternehmen von Google-Diensten ausgeschlossen werden, was erhebliche Auswirkungen auf die Sichtbarkeit und das Marketingpotenzial haben kann.
Darüber hinaus können im Anwendungsbereich der DSGVO drakonische Geldstrafen verhängt werden. Zusätzlich zu den finanziellen Konsequenzen können Verstöße auch zu Reputationsverlust, Kundenvertrauensverlust und langfristigen Geschäftsschäden führen. Daher ist es von entscheidender Bedeutung, dass Unternehmen sich strikt an die Richtlinien von Google und die DSGVO halten und kontinuierlich ihre Datenschutzpraktiken überwachen und aktualisieren.
SCALELINE Datenschutz
SCALELINE Datenschutz bietet maßgeschneiderte Lösungen, um Unternehmen aus dem gesamten DACH-Raum bei der Umsetzung effektiver Datenschutzmaßnahmen zu unterstützen. Durch eine individuelle Analyse der Bedürfnisse und Anforderungen jedes Unternehmens entwickelt SCALELINE Datenschutz maßgeschneiderte Datenschutzkonzepte, die auf die spezifischen Geschäftsprozesse und -strukturen zugeschnitten sind. Dabei werden nicht nur die gesetzlichen Anforderungen berücksichtigt, sondern auch die individuellen Unternehmensziele und -strategien.

Data Literacy als Schlüsselkompetenz
Data Literacy als Schlüsselkompetenz
Lesedauer: 4 Minuten
Digitaler Darwinismus
Change ist nichts Neues. Im Umfeld von Unternehmen ändern sich ständig Faktoren, wie Wettbewerbsstruktur, Marktumfeld oder Nachfrageverhältnisse. Die unternehmerische Bereitschaft, sich permanent zu hinterfragen und zu wandeln, war und ist zur Sicherung einer nachhaltigen Existenzfähigkeit zwingend notwendig. Jedoch haben Geschwindigkeit und Intensität der kontinuierlichen Veränderung eine neue Qualität erreicht. Wandel ist kein Projekt, sondern ein Dauerzustand, in dem sich Unternehmen befinden.
Wir leben in einem digitalen Zeitalter, in dem wir in immer kürzer werdenden Abständen neue Technologien, Apps, Tools und Kommunikationskanäle kennenlernen. Die zunehmende Digitalisierung beeinflusst jedoch nicht nur die Menschen, sondern auch eine sehr große Anzahl von Unternehmen. Die Digitale Transformation wird auf jede Industrie und jeden Service bis in den letzten Winkel Auswirkungen haben.
Wenn Unternehmen nicht ausreichend auf die technologischen und digitalen Veränderungen reagieren, dann entsteht ein digitaler Darwinismus. Technologien und Gesellschaft verändern sich dann schneller als die Fähigkeit von Unternehmen, sich den Veränderungen anzupassen. Unternehmen verlieren den Anschluss auf dem Markt, werden verdrängt und überleben schlimmstenfalls im Zeitalter der Digitalisierung nicht.
Unternehmen stehen daher vor einer sehr großen Herausforderung, der sie sich stellen müssen. Sie müssen sich zum einen mit der digitalen Transformation der Gesellschaft auseinandersetzen und auf diese reagieren. Zum anderen müssen sie digitale Lösungen und Services für ihre Geschäftsfelder entwickeln. Es geht also nicht mehr um das “Ob”, sondern nur noch um das “Wie”. Neben der Stärke braucht es auch die Anpassungsfähigkeit, um sich schnell und kontinuierlich anpassen zu können. Und es braucht Menschen mit den dazu notwendigen Schlüsselkompetenzen.
Mensch und Technologie in Symbiose
In der Biologie gibt es viele symbiotische Beziehungen. Zwischen Arten bestehen gegenseitige Abhängigkeiten, um die ökologische Fitness zu erhöhen. In der Wirtschaft besteht eine solche Abhängigkeit zwischen Mensch und Technologie, da deren Kombination die ökonomische Fitness der Unternehmen mitbestimmt. Wenn Unternehmen im Sinne des darwinistischen „Survival of the fittest and fastest“ das Zeitalter der Digitalisierung überleben wollen, dann müssen die symbiotischen Beziehungen zwischen Mensch und Technologie ermöglicht, hergestellt und genutzt werden.
Die Symbiose zwischen Mensch und Technologie wird die gesellschaftliche und wirtschaftliche Zukunft bestimmen, denn die Zukunft gehört weder dem Menschen noch der Technik alleine. Technologien sind eine Erweiterung von Menschen und deren Möglichkeiten. Die Kombination der Stärken von beiden führt zu besseren Ergebnissen und damit zur digitalen Geschäftsfähigkeit.
Effektivität kann gesteigert werden, weil Mensch und Technologie zusammen ein breiteres Spektrum von Aufgaben bewältigen können. Effizienz kann gesteigert werden, weil Menschen sich auf komplexe Aufgaben konzentrieren können, die Technologie nicht bewältigen kann. Technologie kann als Werkzeug den Menschen helfen, ihre kreativen Fähigkeiten zu erweitern und neue Ideen zu generieren. Mittels der Analyse von Daten können beispielsweise neue Erkenntnisse gewonnen und Handlungsempfehlungen zur Verbesserung abgeleitet werden.
Im Zuge der Digitale Transformation kann Technologie Unternehmen dabei helfen, sich an die schnell verändernden Umgebungen anzupassen, indem schnellere Reaktionszeiten ermöglicht werden. Für die gemeinsame Bewältigung dieser neuen Herausforderungen muss aber sichergestellt werden, dass Mensch und Technologie sich auch gleichzeitig weiterentwickeln. Dazu bedarf es einer synchronen Transformation.
Synchrone Transformation
“In the electric world, change is the only stable factor.”. Das Zitat des Kommunikationstheoretikers Marshall McLuhan ist heute aktueller denn je. Der Wandel ist dabei aber nicht konstant, sondern exponentiell. Oft entwickelt sich Technologie schneller als eine Organisation fähig ist, sich zu verändern. Technologische Herausforderungen werden priorisiert und losgelöst von den menschlichen Herausforderungen behandelt. Mensch und Technologie driften schnell auseinander.
Wenn Technologie sich schneller weiterentwickelt als der Mensch und der Mensch den Anschluss verliert, dann kann das schwerwiegende Konsequenzen haben. Angefangen bei geringerer Effizienz und Produktivität über den Verlust wettbewerbsfähiger Vorteile bis hin zu mangelnder Akzeptanz von Innovationen. Dadurch kann die digitale Transformation eines Unternehmens ausgebremst, behindert oder sogar verhindert werden. Dies gilt es durch eine synchrone Transformation und eine gleichzeitige Weiterentwicklung von Mensch und Technologie zu vermeiden.
Dazu muss die Beziehung zwischen Mensch und Technologie in den Fokus gerückt und die Weiterentwicklung von Mensch und Technologie in Einklang und Gleichklang gebracht werden. Der wichtigste Schritt ist die Entwicklung einer Strategie zur Personalentwicklung, die sicherstellt, dass die Menschen in einem Unternehmen über die richtigen Fähigkeiten und Kompetenzen verfügen, um die digitale Transformation erfolgreich umzusetzen.
Neben der Einstellung von Mitarbeitern mit den benötigten Fähigkeiten spielt dabei die Entwicklung interner Talente und die gezielte Weiterbildung von Mitarbeitern eine wichtige Rolle. Die Weiterentwicklung muss dabei kontinuierlich mit der aktuellen Entwicklung der Technologie synchronisiert und in einem agilen Prozess und mittels Micro Learning durchgeführt werden. So werden die richtigen Schlüsselkompetenzen richtig aufgebaut.
Datenkompetenz als Schlüsselkompetenz
Für Unternehmen, die sich auf dem Weg der digitalen Transformation befinden, sind neben den Technologien selber auch die entsprechenden Technologie-Kompetenzen unerlässlich. Beide sind untrennbar miteinander verbunden. Ohne die Fähigkeiten und Kenntnisse zur effektiven und effizienten Nutzung von Technologie kann kein Nutzen entstehen. Unternehmen müssen folglich über qualifizierte Mitarbeiter verfügen, um Technologie wertschöpfend zu nutzen und dadurch wettbewerbsfähig und erfolgreich zu bleiben.
Zwei dieser Technologie-Kompetenzen sind die Software-Nutzungskompetenz und die Datenkompetenz. Beide Kompetenzen sind eng miteinander verknüpft und ergänzen sich und beide sind wichtige Faktor für den Erfolg der digitalen Transformation. Mitarbeiter müssen über beide Kompetenzen verfügen. Die Datenkompetenz umfasst dabei den Umgang mit Daten, deren Management und deren Analyse. Mitarbeiter müssen befähigt werden, Daten effektiv und effizient zu nutzen und so wertvolle Erkenntnisse zu gewinnen.
Im Kontext der Digitalen Transformation benötigen insbesondere Menschen aus Unternehmensbereichen entlang der Kunden-Wertschöpfungskette, wie Marketing, Vertrieb, Service und Produktentwicklung, entsprechende Skills als Ergänzung zu ihren fachlichen Kernkompetenzen. Der rollenspezifische Aufbau dieser Kompetenzen sollte daher zum festen Weiterbildungsprogramm in Organisationen gehören.
Ausblick
Für die Umsetzung dieses Vorhabens lohnt sich für Personalverantwortliche ein Blick auf die Mechanismen der Gaming-Industrie. Charakterentwicklungspfade, auch Skilltrees genannt, sind im Gaming bereits etablierte Mechanismen, die sich gut auf das Personalwesen übertragen lassen. In unserem nächsten Artikel zeigen wir auf, was Personaler von Rollenspielen lernen können und wie People Analytics und Up-Skilling dabei helfen können, die Herausforderungen der synchronen Transformation zu meistern.

Spenderanalyse mit KI - Teil II
Spenderanalyse mit KI - Teil II
Lesedauer: 7 Minuten
In dieser zweiteiligen Fallstudie begleiten wir die fiktive Non-Profit-Organisation Zero Hunger e.V. auf ihrer Reise hin zu einer datengetriebenen Organisation. Im ersten Teil haben wir aufgezeigt, wie der fiktive Verein eine hausweite Datenstrategie inklusive Tracking-Konzept und KPI-Framework einführt. Diese Datenstrategie ist der Startpunkt für den nächsten Schritt von Zero Hunger: Spenderprognosen mithilfe von Künstlicher Intelligenz ermitteln. Mithilfe von Technologien des Machine Learnings (ML) sollen Prognosen über das Verhalten von Spenderinnen und Spendern getroffen werden. Diese sollen die Basis bilden für eine Kampagne zur Gewinnung von neuen Dauerspendern. Wie das gelingen kann, beschreiben wir in diesem Teil der fiktiven Fallstudie.
Künstliche Intelligenz im Fundraising
So genannte Spenderprognosen (Predictive Analytics) sind nur eine Einsatzmöglichkeit von KI-getriebenen Technologien im Fundraising. Insbesondere im Online-Marketing können Large Language Modelle (LLM) wie ChatGPT hilfreiche Unterstützung bieten, z.B. bei der Recherche von passenden SEO-Keywords, beim Texten von Anzeigen und von Landingpages für Spendenkampagnen oder auch bei der Beantwortung von Fragen im Spenderservice.
Mindset und Organisationskultur
Damit Technologien Künstlicher Intelligenz im Fundraising eingesetzt werden können, braucht es eine Führungskultur in der NGO, die datenbasierte Entscheidungen trifft und KI als Chance für die Organisation versteht. Durch den Aufbau einer Datenstrategie hat es Zero Hunger geschafft, dieses Mindset im Verein Stück für Stück aufzubauen. Mitarbeitende und Führungskräfte begegnen digitalen Themen mit Offenheit. Entscheidungen werden nicht aus persönlichen Erfahrungen heraus getroffen, sondern auf der Basis von Datenanalysen. Es herrscht Einigkeit, dass gegenüber dem Spender transparent kommuniziert wird, wie seine Daten gespeichert und verarbeitet werden. Daten werden DSGVO-konform gesammelt, die Auswahl von passenden KI-Tools findet unter ethischen Gesichtspunkten statt.
Spendervorhersagen treffen mithilfe von Predictive Analytics
Eines der größten Potentiale von Künstlicher Intelligenz im Fundraising liegt in der Prognose von Spenderverhalten. Darauf basierend können auf den Spender zugeschnittene Fundraisingaktivitäten geplant und umgesetzt werden. Solche prädikativen Analysen (predictive analytics) erkennen Muster, Trends und Verbindungen innerhalb vorhandener Spenderdaten. Somit können Vorhersagen darüber getroffen werden, wie hoch die Erfolgswahrscheinlichkeit einer Spendenkampagne bei einem konkreten Spendersegment ist. Um Spenderprognosen mittels Künstlicher Intelligenz erstellen zu können benötigt es einen möglichst großen Input an Spenderdaten mit verschiedenen Parametern. Dieser kann beispielsweise aus einem Data Warehouse stammen. Algorithmen des Machine Learnings werden darauf optimiert, Korrelationen in den Eingabedaten zu erkennen und Vorhersagen zu treffen.
Zielsetzung
Um die Zielgruppe der Dauerspender zu verstehen, lohnt sich ein Blick auf den Spender-Funnel. So könnte der Funnel für diese fiktive Fallstudie aussehen:
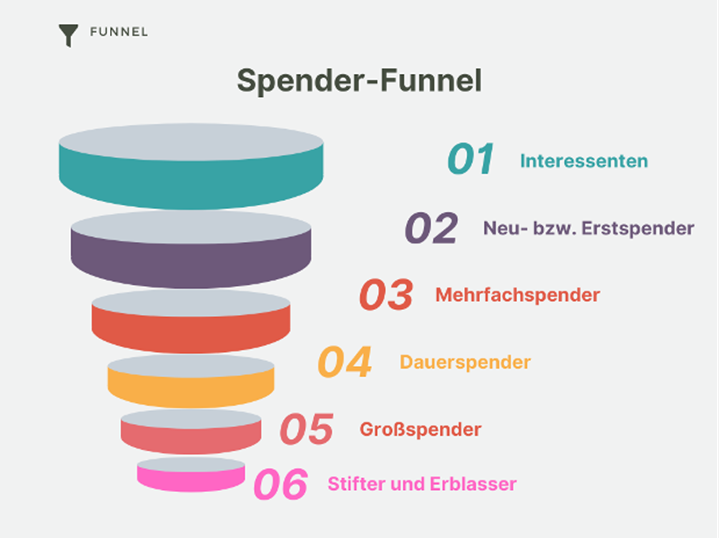
Der Funnel beschreibt die verschiedenen Schritte der Spenderbindung und -entwicklung. Je höher die Stufe, desto engagierter und wertvoller ist der Spender. Zero Hunger hat das Ziel, den Anteil der Dauerspender innerhalb der nächsten drei Jahren zu verdoppeln. Das heißt, Zero Hunger muss in dieser Zeit möglichst viele Mehrfachspender in Dauerspender überführen.
Dementsprechend definiert Zero Hunger folgende Zielsetzung für die prädikative Analyse mittels Machine Learning:
Identifiziere mir unter den Neu- und Mehrfachspendern alle Spender, die das Potential haben, Dauerspender zu werden.
Diese Spender werden von Zero Hunger mit einer crossmedialen Dauerspender-Kampagne bespielt. Die Kampagne besteht aus einem Print-Mailing, verzahnt mit einer Kampagnen-Landingpage auf der Website von Zero Hunger. Im Vergleich zu Kampagnen ohne vorherige prädikative Analyse minimiert Zero Hunger bei dieser Kampagne die Streuverluste, die es in der Regel bei jeder Spendenkampagne gibt. Es werden gezielt nur die Personen angeschrieben, die laut ML-Modell am nächsten an das Profil eines Dauerspenders heranreichen. Dadurch wird die Conversion-Rate optimiert und der ROI gesteigert.
Exkurs: Beispieltraining
Um das Verfahren von Predictive Analytics mithilfe von Machine Learning zu erklären, haben wir für diesen Blog-Beitrag einen Trainingsdatensatz aus dem E-Commerce-Bereich genutzt und ein entsprechendes Modell auf diesen Daten trainiert. Die gesamte Dokumentation des Trainings kann hier nachgelesen werden:
Im Folgenden fassen wir die wichtigsten Schritte zusammen. Das Training besteht aus vier Schritten, die einen Zyklus bilden:
- Explore and Adapt: man schaut sich verschiedene Eigenschaften des Datensatzes an, und versucht die Zusammenhänge zwischen den Daten genauer zu verstehen. Dann passt man das Modell bzw. den Datensatz an die Erkenntnisse an.
- Train: das Modell trainieren
- Evaluate: die Performance anhand von Daten messen, die zuvor nicht im Training verwendet wurden
- Inference/Go-Live: Verwendung des Modells im Echtbetrieb
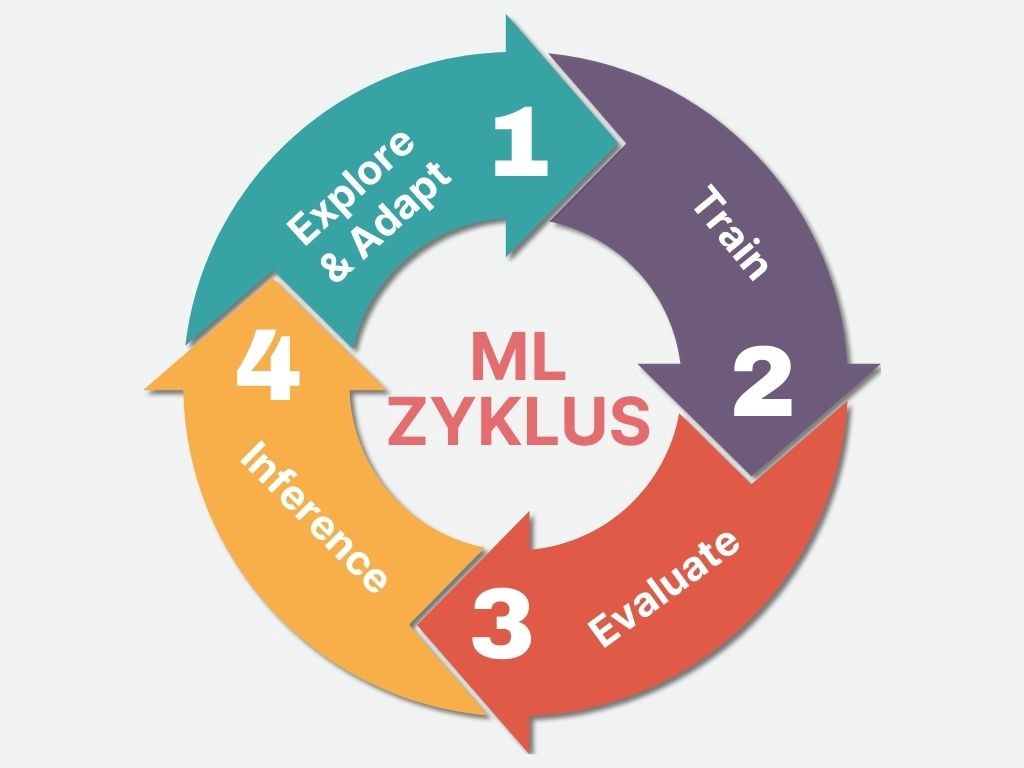
Schritt 1: Explore and Adapt
Zunächst wird der Datensatz hinsichtlich seiner Eigenschaften analysiert. Der Datensatz ist ein Test-Datensatz von der Plattform Kaggle, einer von Google betriebenen Online-Community für Datenwissenschaftler. Der Datensatz ist auf Kaggle populär, aber er stammt aus dem Bereich des E-Commerce. Die Grundzüge des Vorgehens lassen sich aber auch auf NGO übertragen.
Wir beschränken uns in diesem Beispiel-Training auf eine einfache Frage: Welcher Kunde erzielte in den letzten zwei Jahren mehr und welcher weniger als 1.000 € Umsatz. Übertragen auf das Szenario von Zero Hunger wären die Kunden mit mehr als 1.000 € Umsatz die potenziellen Dauerspender, die mit einer Kampagne aktiviert werden sollen. Die Spender unter 1.000 € Umsatz fallen als Zielgruppe der Dauerspender-Kampagne heraus. Die Wahrscheinlichkeit, dass diese Spender konvertieren, ist zu gering.
Unser Test-Datensatz hat 2.240 Zeilen (Kunden) mit insgesamt 29 Spalten/Dimensionen. Die Dimensionen beschreiben den Kunden. Es handelt sich beispielsweise um demografische Daten (z.B. ‚Year_Birth‘), Einkommen (‚Income‘), Angaben zum Familienstatus (‚Marital_Status), Abschluss (‚Education‘) usw. Da die Testdaten aus dem E-Commerce-Bereich stammen, sind auch Dimensionen aufgeführt, die für den NGO-Bereich nicht relevant sind.
| ID | Year_Birth | Education | Marital_Status | Income | Kidhome | Teenhome | Dt_Customer | Recency | MntWines | MntFruits | MntMeatProducts | MntFishProducts | MntSweetProducts | MntGoldProds | NumDealsPurchases | NumWebPurchases | NumCatalogPurchases | NumStorePurchases | NumWebVisitsMonth | AcceptedCmp3 | AcceptedCmp4 | AcceptedCmp5 | AcceptedCmp1 | AcceptedCmp2 | Complain | Z_CostContact | Z_Revenue | Response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5524 | 1957 | Graduation | Single | 58138.0 | 0 | 0 | 04-09-2012 | 58 | 635 | 88 | 546 | 172 | 88 | 88 | 3 | 8 | 10 | 4 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 1 |
| 1 | 2174 | 1954 | Graduation | Single | 46344.0 | 1 | 1 | 08-03-2014 | 38 | 11 | 1 | 6 | 2 | 1 | 6 | 2 | 1 | 1 | 2 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2 | 4141 | 1965 | Graduation | Together | 71613.0 | 0 | 0 | 21-08-2013 | 26 | 426 | 49 | 127 | 111 | 21 | 42 | 1 | 8 | 2 | 10 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 3 | 6182 | 1984 | Graduation | Together | 26646.0 | 1 | 0 | 10-02-2014 | 26 | 11 | 4 | 20 | 10 | 3 | 5 | 2 | 2 | 0 | 4 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 4 | 5324 | 1981 | PhD | Married | 58293.0 | 1 | 0 | 19-01-2014 | 94 | 173 | 43 | 118 | 46 | 27 | 15 | 5 | 5 | 3 | 6 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2235 | 10870 | 1967 | Graduation | Married | 61223.0 | 0 | 1 | 13-06-2013 | 46 | 709 | 43 | 182 | 42 | 118 | 247 | 2 | 9 | 3 | 4 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2236 | 4001 | 1946 | PhD | Together | 64014.0 | 2 | 1 | 10-06-2014 | 56 | 406 | 0 | 30 | 0 | 0 | 8 | 7 | 8 | 2 | 5 | 7 | 0 | 0 | 0 | 1 | 0 | 0 | 3 | 11 | 0 |
| 2237 | 7270 | 1981 | Graduation | Divorced | 56981.0 | 0 | 0 | 25-01-2014 | 91 | 908 | 48 | 217 | 32 | 12 | 24 | 1 | 2 | 3 | 13 | 6 | 0 | 1 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2238 | 8235 | 1956 | Master | Together | 69245.0 | 0 | 1 | 24-01-2014 | 8 | 428 | 30 | 214 | 80 | 30 | 61 | 2 | 6 | 5 | 10 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2239 | 9405 | 1954 | PhD | Married | 52869.0 | 1 | 1 | 15-10-2012 | 40 | 84 | 3 | 61 | 2 | 1 | 21 | 3 | 3 | 1 | 4 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 1 |
Bezogen auf das Szenario von Zero Hunger käme dieser Datensatz aus dem Data Warehouse. Durch die sauber aufgesetzte Datenstrategie hat der Verein Zugriff auf qualitativ hochwertige Spenderdaten und eine sauber strukturierte, breite Datenbasis, die als Input für das Machine Learning Modell dient. Die Spenderdatensätze können dadurch einfach per CSV-/JSON-Export aus dem Data Warehouse exportiert und für das Training verwendet werden.
Ziel des Trainings ist es, die Kunden in zwei Gruppen aufzuteilen:
- Kunden, die mehr als 1.000 € Umsatz generieren: 1.000 +
- In unserem Szenario sind dies die potenziellen Dauerspender, d.h. die Zielgruppe der Dauerspender-Kampagne
- Kunden, die weniger als 1.000 € Umsatz generieren: 0-999
- In unserem Szenario sind dies alle anderen Einzel- und Mehrfachspender
Diese Kundengruppen werden später als die beiden Ziele/Labels des Trainings dienen. Das Modell soll lernen, die Kundengruppe (1.000 + oder 0-999) vorherzusagen. Für das Training des Modells auf diese beiden Kundengruppen werden nur 7 der ursprünglichen 29 Dimensionen genutzt, und zwar die 7, die den meisten Aufschluss über die gesuchten Kundengruppen geben. Dies haben wir durch mehrere Versuche mit unterschiedlichen Kombinationen und den beiden Visualisierungsverfahren (t-SNE und PCA) herausgefunden.
Visualisierung des Datensatzes mit der t-SNE Methode
Bei dieser Methode der Daten-Visualisierung werden die 7-Dimensionen der Eingabetabelle auf zwei Dimensionen reduziert. Diese 2D-Repräsentation kann man in einem Graphen darstellen:
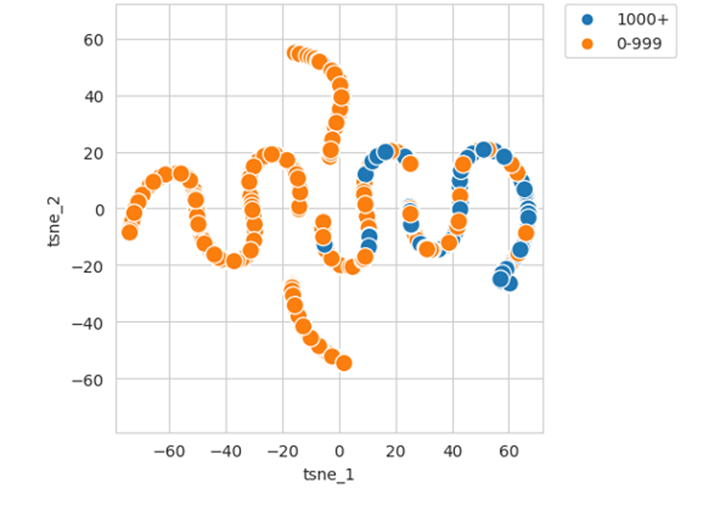
In der Grafik sieht man, dass es zwar eine Überlappung zwischen beiden Gruppen gibt, sich eine Vielzahl von orangenen (0-999) Kunden aber tatsächlich auf der linken Bildhälfte befindet und die blauen 1000+-Kunden auf der rechten Seite Platz finden. Das legt nahe, dass es tatsächlich möglich sein wird, anhand der o.g. Eingabedaten die beiden Kundengruppen zu unterscheiden. Neben der t-SNE-Methode wurde in der Explore-Phase eine weitere Visualisierungsmethode angewendet: PCA. Auch diese Methode zeigt, dass die beiden gewünschten Kundengruppen voneinander unterscheidbar sind.
Schritt 2: Das Training
Da die Visualisierungen eine Unterscheidung der Eingabedaten anhand der ausgewählten 7 Dimensionen erlauben, kann man nun mit dem Training beginnen.
Das Training wird für 50 Epochen durchgeführt. Dies sind Teilschritte des Trainings. In jeder Epoche wird der Trainingsdatensatz einmal ins Modell gegeben. Dabei wird der Fehler zwischen erwartetem und tatsächlichem Label (0,1) bestimmt. Anschließend wird das Netzwerk optimiert, sodass die Fehlerwahrscheinlichkeit abnimmt.
Bevor wir mit dem Training beginnen, muss jedoch der Datensatz in 3 Teile eingeteilt werden. Die Aufteilung wird automatisiert und zufällig vorgenommen. Der überwiegende Anteil der Daten (z.B. 75%) ist im Trainingsdatensatz und wird für die Optimierung des Modells verwendet. Zwei weitere Teile (z.B. jeweils 12,5%) werden zur Evaluation der Genauigkeit (sog. Accuracy) außerhalb der Optimierung verwendet.
Schritt 3: Die Evaluation
Nach dem Durchlaufen aller Epochen kommen die Testdaten ins Spiel. Mit diesem Datensatz werden weitere Evaluationen am Ende des Trainings durchgeführt. Passt das trainierte Modell gut zu den Testdaten, sagt das Modell mit einer hohen Genauigkeit voraus, welcher Kunde voraussichtlich mehr als 1.000 € Umsatz generiert und welcher weniger.
In unserem Beispiel-Training kommen wir auf eine Genauigkeit von 87,87 %. Das bedeutet, wenn 100 Kunden in das Netzwerk geladen werden, liegt das Netzwerk bei knapp 88% mit der Einschätzung richtig. Die Genauigkeit je Kundengruppe ergibt Folgendes:
- Wenn das Netzwerk den Wert 0-999 vorhersagt, liegt es in 90% der Fälle richtig
- Wenn das Netzwerk den Wert 1000+ vorhersagt, liegt es in 77% der Fälle richtig
Die unterschiedliche Genauigkeit könnte damit zu erklären sein, dass im Trainingsdatensatz wesentlich mehr Kunden mit einem Umsatz zwischen 0-999 € enthalten waren.
Schritt 4: Der Einsatz des Modells
Nachdem wir die Performance anhand von Daten gemessen haben, die zuvor nicht im Training verwendet wurden, und die Genauigkeit zufriedenstellend ist, können wir das Modell nun im Echtbetrieb einsetzen.
Wir haben zwei fiktive Kunden und müssen für diese folgende 7 Parameter kennen: Age, Income, Education, Marital_Status, Kidhome, Teenhome, Dt_Customer_Years
Unsere fiktiven Kunden sind:
Margret Musterfrau
- Alter: 56
- Jahreseinkommen: 100000
- Bildungsniveau: Phd
- Familienstand: Married
- Anzahl der Teenager im Haushalt: 2
- Anzahl der Kinder im Haushalt: 0
- Kunde seit: 3
Max Mustermann
- Alter: 28
- Jahreseinkommen: 25000
- Bildungsniveau: Graduated
- Familienstand: Divorced
- Anzahl der Teenager im Haushalt: 0
- Anzahl der Kinder im Haushalt: 3
- Kunde seit: 2
Gibt man diese fiktiven Kunden ins Modell erhält man folgendes Ergebnis des Trainings:
- Margret: 1000+
- Max: 0-999
Übertragen auf das Szenario von Zero Hunger kann die NGO aus dieser prädikativen Analyse den Schluss ziehen, dass Margret Musterfrau in jedem Fall zu den Adressaten der Dauerspender-Kampagne zählt. Die Erfolgschancen, dass Margret auf die Kampagne konvertiert, sind laut Modell sehr hoch. Max Mustermann hingegen kann bei der Kampagne vernachlässigt werden, da die Wahrscheinlichkeit, ihn in einen Dauerspender zu überführen, laut Modell sehr gering ist.
Erfolgsmessung
Mithilfe des KPI-Frameworks, das Zero Hunger für die Dauerspender Kampagne aufgesetzt hat, kann der Erfolg der Kampagne gemessen werden. Diese Erfolgsmessung ist zugleich auch der Gradmesser für die Güte des Machine Learning Modells. Ziel ist es, durch die vorherige KI-basierte Spenderanalyse die Responserate des Dauerspendermailings im Vergleich zu Mailings ohne vorherige Analyse zu erhöhen, den Return on Invest zu steigern sowie die durchschnittlichen Kosten pro Dauerspender zu senken. Mittel- bis langfristig soll durch eine erfolgreiche Spenderansprache die Spenderloyalität insgesamt gesteigert werden. Die Daten aus dem KPI-Framework fließen schlussendlich wieder zurück in das Machine Learning Modell. Dadurch wird das Modell fortlaufend trainiert und die Spenderprognose weiter optimiert.
Fazit
Diese fiktive Case Study von Zero Hunger zeigt die Entwicklung eines gemeinnützigen Vereins mit geringem Reifegradlevel hin zu einer datengetriebenen Organisation, die mithilfe von KI-basierten Spenderprognosen die Effektivität ihrer Fundraising-Kampagnen erheblich steigert.
Durch das Beispiel-Training mit einem E-Commerce-Datensatz konnten wir die grundlegenden Schritte der prädikativen Analyse mittels Machine Learning beschreiben. Die Einteilung von Kunden in Klassen mit einem Umsatz über und unter 1.000 EUR spiegelt die Unterscheidung zwischen möglichen Dauerspendern und weniger langfristig engagierten Unterstützern wider. Diese Anpassung auf den gemeinnützigen Sektor zeigt das enorme Anwendungspotential, das KI-basierte Spenderprognosen im Fundraising bieten.
Non-Profit-Organisationen können mithilfe von Machine Learning ihre Spenderdaten analysieren, um potenzielle Dauerspender zu identifizieren. Dieser Ansatz erlaubt es den NGOs, ihre Ressourcen gezielt einzusetzen, um jene Unterstützer anzusprechen, die das größte Potential haben, langfristige Bindungen einzugehen.
Unsere Empfehlung an NGOs ist daher klar: Es lohnt sich, die Schätze in den eigenen Spenderdaten mithilfe von KI zu heben. Eine organisationsweise Datenstrategie und eine nachhaltige Datenkultur bieten dafür ein stabiles Fundament.
Die Fallstudie wurde zusammen mit dem IT-Büdchen erarbeitet. Das IT-Büdchen unterstützt insbesondere NGO dabei, Kampagnen zu gestalten, zu kommunizieren, zu steuern und zu messen.

Spenderanalyse mit KI - Teil I
Spenderanalyse mit KI - Teil I
Lesedauer: 7 Minuten
Künstliche Intelligenz (KI) und maschinelles Lernen bieten für NGO vielversprechende Ansätze im Fundraising. So können beispielsweise mithilfe von KI-getriebenen Prozessen Prognosen erstellt werden, welche Unterstützer das größte Potenzial haben, langfristige Dauerspender zu werden. Doch bevor in die Welt von Prognosen und Vorhersagen eingetaucht werden kann, muss sichergestellt sein, dass eine solide Basis für datengestütztes Arbeiten vorliegt.
Einführung in die fiktive Fallstudie
Um die im folgenden Artikel vorgestellten Methoden möglichst praxisnah zu beschreiben und vorzustellen, haben wir ein fiktives Szenario entwickelt. Dieses Szenario umfasst die fiktive Non-Profit-Organisation Zero Hunger e.V.
Wer ist Zero Hunger?
Zero Hunger wurde 1985 als Reaktion auf die große Hungersnot in Äthiopien gegründet. Inzwischen fördert die NGO Ernährungsprojekte in 180 Ländern in Afrika, Lateinamerika und Südostasien.
Das Fundraising von Zero Hunger
Das jährliche Spendenvolumen in Höhe von 142,6 Mio. € speist sich zu 30 % aus staatlichen Mitteln. Vor 5 Jahren lag dieser Anteil noch bei 45 %. Um dem Rückgang von staatlichen Mitteln entgegenzuwirken, hat Zero Hunger eine Dauerspender-Strategie entwickelt. Innerhalb der nächsten 3 Jahre soll sich der Anteil der Dauerspender*innen, die mindestens 50 EUR im Monat spenden, verdoppelt haben. Um dieses Ziel zu erreichen, möchte Zero Hunger eine Kampagne zur Gewinnung von neuen Dauerspendern aufsetzen.
Datengrundlage für das Fundraising
Dem Verein stehen für die Kampagne verschiedenste Fundraising-Kanäle und -Aktivitäten zur Verfügung, z.B. Print-Mailings, Website, Social Media Fundraising, Newsletter etc. Das Problem: Die Daten, die durch die Fundraising-Aktivitäten produziert werden, sind nicht systematisch erfasst. Viele Daten liegen in einzelnen Daten-Silos und sind nicht miteinander vernetzt. Dementsprechend kann der Erfolg der Dauerspender-Kampagne nicht strategisch ausgewertet werden.
Fundraising und KI
Die frisch eingesetzte Geschäftsführerin von Zero Hunger ist ein großer Fan von datengetriebenen Entscheidungen und offen gegenüber Innovationen. Sie nimmt die Dauerspender-Kampagne zum Anlass, um zusammen mit einer externen Beratung eine Datenstrategie zu erarbeiten und zu implementieren, um so den eigenen Digital Analytics Reifegrad zu steigern. Die Datenstrategie soll jedoch nur der erste Schritt sein. Im zweiten Schritt sollen mittels KI und Machine Learning Prognosen über das Verhalten von Spenderinnen und Spendern getroffen werden. Diese Prognosen sollen die Basis für die Kampagne zur Gewinnung von neuen Dauerspendern bilden.
Bevor der fiktive Verein Zero Hunger also in der Lage ist, mittels KI und Predictive Analytics die Kampagne zur Gewinnung von Dauerspendern zu optimieren, muss erst die Grundlage für eine datengetriebene Organisation geschaffen werden. Bis jetzt befindet sich die fiktive NGO Zero Hunger auf einem niedrigen Reifegradlevel. Das bedeutet, dass Daten weder systematisch erfasst noch für die Optimierung der eigenen Fundraising-Maßnahmen genutzt werden. Um die ersten Schritte hin zu einem datengetriebenen Verein zu machen und eine nachhaltige Datenkultur zu etablieren, bildet ab sofort die organisationsweite Datenstrategie die Basis des operativen Handelns.
Schritt 1: Zielsetzung
Um neue Dauerspender zu gewinnen, setzt Zero Hunger auf eine Vielzahl von Fundraising-Kanälen und -Aktivitäten. Die verschiedenen Social-Media-Kanäle oder Newsletter sind super Möglichkeiten, um Awareness für verschiedene Kampagnen und die Mission des Vereins zu generieren. Entlang der Donor Journey im digitalen Fundraising ist allerdings die eigene Website der wichtigste Touchpoint, denn über diese konvertieren Besucher letztendlich zu Spendern. Für Zero Hunger ist es also essenziell, sowohl den Traffic aus den verschiedenen Marketingkanälen als auch den Traffic auf der eigenen Website messbar zu machen und mithilfe von datengetriebenen Insights Handlungsempfehlungen daraus abzuleiten. Dafür muss sich Zero Hunger zunächst folgende Frage beantworten: Warum werden Daten gesammelt und was soll damit erreicht werden?
Mehr Kanäle bedeuten mehr Daten – auch für Zero Hunger. Da bis jetzt keine organisationsweite Datenstrategie vorlag, liegen die Daten der verschiedenen Kanäle dezentral in einzelnen Datensilos. Das Team weiß also gar nicht, welche Daten innerhalb der Dauerspenderkampagne erfasst werden sollen, wo diese hinfließen sollen und in welcher Form diese aufbereitet werden müssen, um eine saubere Entscheidungsgrundlage liefern zu können. Ein einheitliches und allgemeingültiges Zielbild sorgt an dieser Stelle für Ordnung. In diesem sollen die strategischen Ziele der Dauerspender-Kampagne definiert und an das Team kommuniziert werden. Im Zuge der Entwicklung einer Datenstrategie erarbeitet der Verein gemeinsam mit der externen Beratung ein KPI-Framework.
Folgende Fragen muss sich Zero Hunger vor Erstellung des KPI-Frameworks beantworten können:
- Können wir unser strategisches Ziel (Spendenvolumen steigern) in kleinere (Teil-)ziele schneiden?
- Welche Kennzahl eignet sich am besten für die Messung der Zielerreichung?
- Welcher Zielwert stellt einen Erfolg dar?
- Wie möchte ich die einzelnen Kennzahlen segmentieren können?
Mithilfe eines KPI-Frameworks kann Zero Hunger die Erreichung übergeordneter (Teil-)Ziele und die Performance der wichtigsten Kanäle messbar machen. Um die Zielerreichung der Maßnahmen hinterher auf einen Blick einsehen zu können, muss jedem Teilziel ein konkreter Key Performance Indicator (KPI) samt Zielwert zugeordnet werden. Die KPI lässt sich anschließend noch weiter segmentieren, um eine granulare Beobachtung verschiedener Kanäle oder Endgeräte zu ermöglichen.
So könnte ein exemplarisches KPI Framework aussehen:
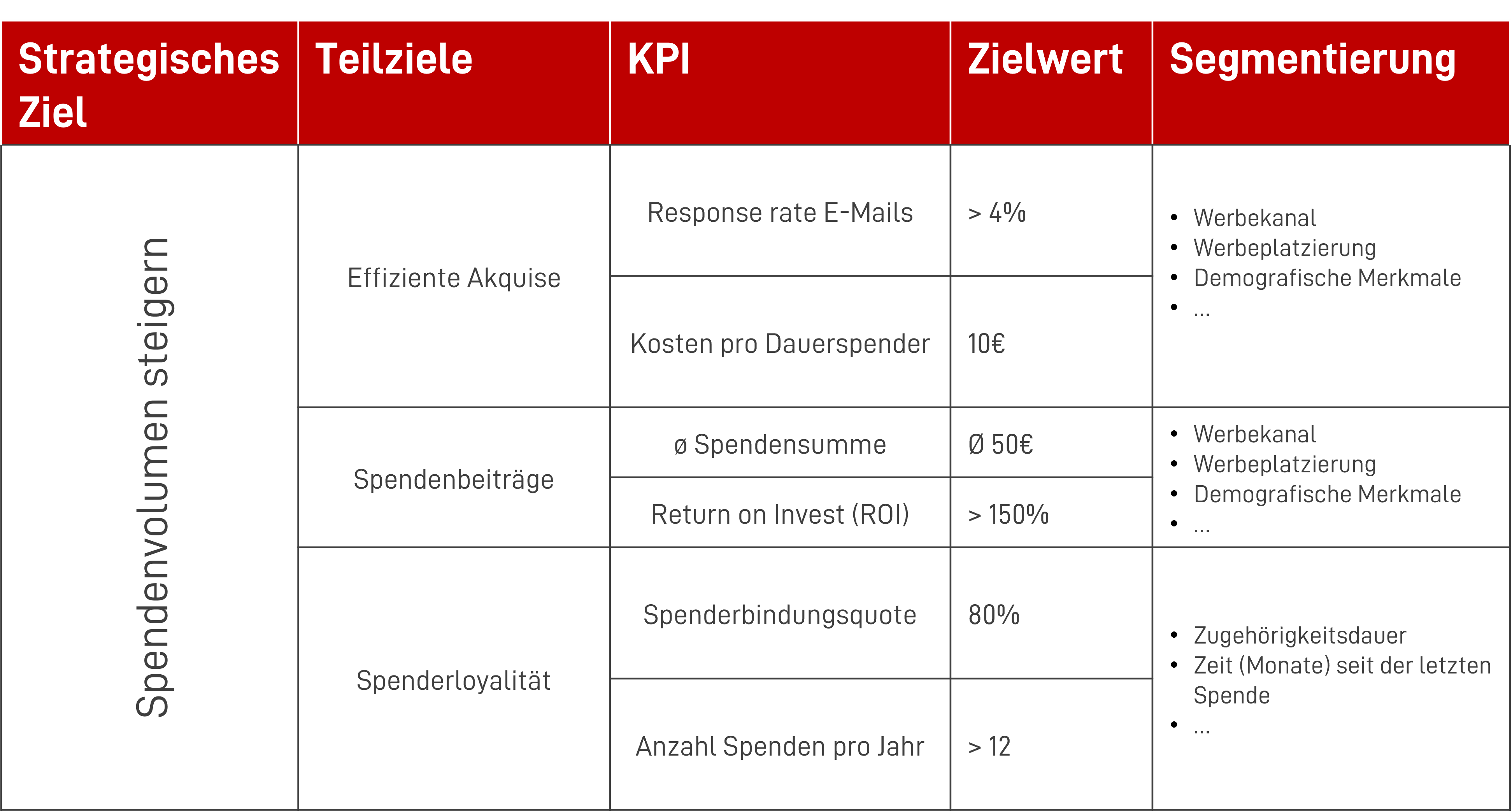
Zero Hunger hat das übergeordnete, strategische Ziel in drei kleinere Teilziele heruntergebrochen. Im ersten Schritt möchte der Verein wissen, wie effizient die Akquise bzw. Ansprache von Dauerspendern verläuft. Dafür betrachtet Zero Hunger die Responserate von bereits erfassten Spendern in den Kanälen Mailing und Telefon. In nächsten Schritt betrachtet Zero Hunger die durchschnittliche Spendensumme pro Dauerspender. Der Zielwert von 50 Euro wurde bereits von der Geschäftsführung kommuniziert. Die Betrachtung des ROI (Return on Investment) stellt sicher, dass das Marketingbudget in den verschiedenen Kanälen effizient eingesetzt wird. Ergänzend dazu möchte Zero Hunger eine hohe Spenderloyalität sicherstellen. Dafür wird, neben dem bloßen Spendenvolumen, auch die Anzahl der Spenden pro Dauerspender sowie die Spenderbindungsquote festgehalten.
Schritt 2: Datenverarbeitungskonzept
Durch das KPI-Framework stellt Zero Hunger sicher, dass die Performance aller relevanten Touchpoints und Datenpunkte innerhalb der Dauerspenderkampagne messbar gemacht wird. Doch um die Daten später auswerten und interpretieren zu können, müssen diese noch bereinigt, zusammengeführt und in eine Datenbank eingespeist werden. Auf Basis der Datenstrategie entwickelt Zero Hunger dafür ein klares Konzept für die interne Datenverarbeitung. Neben den genutzten Fundraising-Kanälen prüft Zero Hunger auch die Möglichkeit, zusätzliche Datenquellen wie CRM-Systeme, Spenderdatenbanken oder externe APIs in den Techstack aufzunehmen. Um das Konzept wie gewünscht ausliefern zu können, entwirft die externe Beratung eine Checkliste für die Geschäftsführung:
- Dateninventar und -quellen
- Welche aktuellen Datenquellen und -kanäle werden von Zero Hunger genutzt?
- Wie relevant sind diese Daten bezüglich der Zielerreichung der Kampagne?
- Technologieauswahl
- Wie sieht der Tool- und Techstack aktuell aus?
- Wie soll dieser zukünftig erweitert werden?
- Datenqualität und Datenbereinigung
- Wie wird eine ausreichend hohe Datenqualität hinsichtlich Genauigkeit, Vollständigkeit und Aktualität sichergestellt?
- Welche Maßnahmen werden zur Bereinigung und Korrektur von Datenfehlern, -lücken und -dubletten durchgeführt?
- Datenvalidierung und -interpretation
- Wie werden die gewonnenen Daten und deren Interpretation validiert?
- Wer ist verantwortlich für die Ableitung von Handlungsempfehlungen?
- Datenintegration und -zusammenführung
- Wo sollen die Daten zusammengeführt werden?
- Wo sollen diese final gespeichert werden?
- Datenschutz und Datensicherheit
- Wie werden personenbezogene Daten gemäß Datenschutzrichtlinien behandelt?
- Welche Sicherheitsvorkehrungen stehen bereits gegen unbefugten Zugriff und Datenlecks?
- Dokumentation
- Wo und in welchem Format wird die Datenstruktur dokumentiert?
Das neue Datenverarbeitungskonzept ermöglicht es Zero Hunger, unter anderem, sowohl strukturierte als auch unstrukturierte Daten betrachten zu können. In der neu eingeführten Data-Lake-Architektur können die Daten dabei in ihrer ursprünglichen Form gespeichert und bei Bedarf abgerufen werden. Um agil auf wechselnde Anforderungen wie größere Datenmengen reagieren zu können, hält Zero Hunger die Datenarchitektur bewusst flexibel. So können zukünftig neue Datenquellen oder Analysetechnologien einfacher integriert werden.
Um eine ausreichende Datenqualität sicherzustellen, etabliert Zero Hunger leichtgewichtige Prozesse zur Datenqualitätskontrolle. Diese geben vor, wie Daten regelmäßig bereinigt werden, um Duplikate, fehlende Werte oder Inkonsistenzen zu beseitigen. Um die Datentransformation zu vereinfachen, nutzt Zero Hunger ein geeignetes Datenmodell, welches die Struktur der gesammelten Daten widerspiegelt und gleichzeitig die Analyseanforderungen unterstützt. Hier werden sowohl die verschiedenen Segmente der Kampagnendaten (z. B. Spender, Kampagnen, Kanäle) als auch die festgelegten KPI berücksichtigt. Auch an dieser Stelle etabliert Zero Hunger unterstützend zur neuen Technologie (ETL-)Prozesse (Extract, Transform, Load), um die Rohdaten in analysierbare Formate zu bringen. Pro Quellsystem muss es jeweils einen eigenen ETL-Prozess geben. Zusätzlich schult Zero Hunger die eigenen Mitarbeiter kleinteilig und rollenspezifisch im Umgang mit neuen Tools oder Technologien. So bauen diese kontinuierlich die benötigte Datenkompetenz für den Umgang mit diesen auf.
Schritt 3: Datenerfassung
Zero Hunger hat nun ein sehr gutes Verständnis davon, welche Daten relevant für die Zielerreichung der Dauerspender-Kampagne sind und wie der interne Datenfluss aussieht. Ohne dieses gemeinsame Zielbild wäre der Verein im Blindflug unterwegs und einer erhöhten Gefahr des zielfremden Handelns im Marketing und Vertrieb ausgesetzt. Allen Stakeholdern im Verein ist nun klar, welche Kanäle gemessen werden und wie generierte Daten intern weiterverarbeitet werden. Ein Blick auf das neu eingeführte KPI-Framework zeigt, welche Datenpunkte die wichtigsten für die Dauerspender-Kampagne sind und welche Kanäle priorisiert werden müssen. Um eine saubere Datenerfassung und eine qualitativ hochwertige Weiterverarbeitung sicherzustellen, erarbeitet Zero Hunger im nächsten Schritt gemeinsam mit der externen Beratung ein Trackingkonzept inklusive Dokumentation.
Im Trackingkonzept werden alle kampagnenspezifischen Trackingaktionen, Parameter und Events festgehalten. Als Grundlage für das Trackingkonzept dient das KPI-Framework. Für die dort definierten KPIs wird detailliert beschrieben, was konkret auf der Website passiert und wie genau der Trigger, also der Auslöser, für jedes einzelne Event auszusehen hat. Anschließend folgt eine technische Definition des Data Layers. In dieser wird festgehalten, welcher Data Layer Push verwendet wird, um beispielsweise Produkt-Impressionen zu erfassen. Zusätzlich dazu müssen noch die Ereignisparameter für Google Analytics definiert werden. Hier muss jedem Ereignisparameter ein Ereigniswert zugeordnet werden. Nach der Implementierung des Trackingkonzeptes folgt noch ein Testing zur Erfolgskontrolle. Eine anschließende Dokumentation der technischen Integration und Konfiguration der eingesetzten Tools ermöglicht weiteren Kolleg*innen sich leichter einzuarbeiten und zukünftige Anpassungen eigenständig durchzuführen.

Technische Definition: Data Layer
Der Data Layer Push der nötig ist, um den Start des Spenden Checkout Prozesses zu messen (Klickinteraktion auf “Jetzt spenden” Button) muss wie folgt implementiert werden:

Event Parameter
Das Start Event des Checkouts wird genutzt, um den ersten Schritt innerhalb des Checkout-Prozesses zu messen.
Die folgenden Variablen werden mit jedem gestarteten Checkout-Prozess übertragen:
Schritt 4: Datenvisualisierung
Zero Hunger ist jetzt auf einem guten Weg, datengetrieben arbeiten zu können und eine Datenkultur etabliert zu haben. Die für die Dauerspender-Kampagne benötigten Daten werden erfasst und entsprechend aufbereitet. Dem Verein fehlt allerdings noch eine Möglichkeit, um die Daten allen Stakeholdern zur Verfügung zu stellen und sie anschaulich zu visualisieren. Erst dann schaffen die erfassten Daten einen Mehrwert und können in die Entscheidungsunterstützung einfließen. Ein sauber aufgesetztes Dashboard visualisiert die relevanten Daten anschaulich und ermöglicht eine Auswertung des IST-Zustandes einer Kampagne bereits mit wenigen Klicks. Für einfache Kampagnen reicht oft ein Standard-Dashboard ohne große Personalisierung. Je nach Tool lassen sich diese vergleichsweise schnell aufsetzen.
Für die Dauerspender-Kampagne hat sich die Geschäftsführung von Zero Hunger für die Einführung eines maßgeschneiderten Dashboards durch externe Beratung entschieden. Dieses ermöglicht eine Betrachtung und Auswertung der Kampagnenkennzahlen auf einen Blick. Damit die gemeinsame Auswertung der Kampagne keine einmalige Angelegenheit bleibt, führt Zero Hunger einen weiteren leichtgewichtigen Prozess für die bestmögliche Nutzung des Dashboards ein. Hierbei wird beschrieben, dass das gesamte Marketingteam in einem monatlichen Review einen genauen Blick auf die Kampagnenperformance wirft. Sollten die festgelegten Ziele nicht erreicht werden, können datengetriebene Entscheidungen bezüglich weiterer Fundraising-Maßnahmen getroffen werden. Wenn der teuer bezahlte Paid-Kanal nicht die benötigten Dauerspender einbringt, kann das Budget neu verteilt und für erfolgreichere Kanäle wie den Newsletter verwendet werden. Ein gutes Fundraising-Dashboard trägt maßgeblich dazu bei, zielfremdes Handeln zu reduzieren und die Marketingausgaben zu senken. Dieser datengetriebene Ansatz erleichtert auch das Testen neuer Maßnahmen, da der (Miss-)Erfolg deutlich und zeitnah nachgewiesen ist.
So könnte das Dashboard in der fiktiven Fallstudie aussehen:

Fazit
Die Geschäftsführerin von Zero Hunger blickt stolz auf das frisch geschaffene KPI-Framework. Zusammen mit dem Datenverarbeitungs- und dem Tracking-Konzept wurde eine Basis geschaffen, um Fundraising-Aktivitäten ab sofort systematisch messen und auswerten zu können. Der Verein ist nun in der Lage, datengetriebene Entscheidungen für das Fundraising des Vereins zu treffen.
Nun möchte der Verein den nächsten digitalen Reifegrad erreichen: Mit Technologien des Machine Learnings (ML) sollen Prognosen über das Verhalten von Spenderinnen und Spendern getroffen werden. Diese Prognosen sollen die Basis für die geplante Dauerspender-Kampagne bilden.
Im nächsten Teil der fiktiven Fallstudie zeigen wir auf, wie auf Basis der neu geschaffenen Grundlage eine Onboarding Kampagne für Dauerspender mithilfe von Predictive Analytics aufgezogen werden kann.
Die Fallstudie wurde zusammen mit dem IT-Büdchen erarbeitet. Das IT-Büdchen unterstützt insbesondere NGO dabei, Kampagnen zu gestalten, zu kommunizieren, zu steuern und zu messen.

Mit der richtigen Strategie zu Google Analytics 4 – Fünf Tipps für eine gelungene Migration
Mit der richtigen Strategie zu Google Analytics 4 – Fünf Tipps für eine gelungene Migration
Lesedauer: 6 Minuten
Google Analytics ist seit Jahren das am meisten eingesetzte Webanalyse-Tool im Markt. Um den wachsenden Anforderungen gerecht zu werden, hat der Internetgigant seine Lösung nun signifikant weiterentwickelt. Das zieht für alle Anwender eine große Umstellung nach sich. Die neue Lösung Google Analytics 4 (GA4) wird das bisherige Universal Analytics (UA) ersetzen. Dieses wird in Kürze komplett abgeschaltet.
Bereits ab dem 1. Juli 2023 werden in standardmäßigen Universal Analytics Properties keine neuen Treffer mehr verarbeitet. Universal Analytics 360 Properties können noch bis zum 1. Juli 2024 Daten erfassen. Wer Universal Analytics verwendet, sollte spätestens jetzt eine Strategie für den Umstieg auf GA4 entwickeln oder genau prüfen, ob eventuell eine andere Webanalyse-Lösung für die gewünschten Ziele infrage kommt.
Wenn Sie sich jetzt strategisch um die Migration kümmern, können Sie viel Potenzial freischalten: Google verspricht für seine neue Lösung neben verbesserten Analyse- und Visualisierungsmöglichkeiten insbesondere Zukunftssicherheit, da GA4 auch ein datenschutzkonformes, serverseitiges Tracking ermöglicht. Die Prognosen sollen dank Machine Learning präziser werden; zudem lässt sich das Tool gut mit anderen Lösungen im Google-Universum verzahnen.
Doch die Uhr tickt: Bis einschließlich 30. Juni 2023 können Unternehmen in standardmäßigen Universal Analytics-Properties noch Daten erheben und verwenden. Ab dem 1. Juli 2023 ist es nur noch möglich, auf zuvor verarbeitete Daten in der Universal Analytics-Property zuzugreifen. Und auch das ist nur für sechs Monate garantiert. Anschließend werden Universal Analytics-Properties nicht mehr zur Verfügung stehen. Ein konkretes Datum für das komplette Abschalten will Google in Kürze bekanntgeben. Die gute Nachricht: Mit der richtigen Strategie kann schnell und sicher auf GA4 umgestellt werden. Für einfache Setups ist eine Migration meist in ein oder zwei Wochen erledigt. Damit Sie ein Gefühl für das neue Tool bekommen, hat Google ein Demo-Konto eingerichtet.
Wie bei jeder Umstellung lauern allerdings auch hier Tücken. Im Worst Case können Daten verloren gehen, Analysen unterbrechen oder sogar Umsätze ausfallen, wenn bei der Migration Fehler gemacht werden und man zeitweise im Blindflug agiert. Man muss beachten, dass es sich nicht um ein einfaches Update, sondern quasi um ein neues Tool handelt. Bestehende Konten können nicht per copy&paste „übernommen“ werden. Stattdessen müssen neue GA4-Properties konfiguriert werden. Ebenso kann es bei der Umstellung zu Unstimmigkeiten in der Auswertung kommen, wenn nicht sauber migriert wird.
Sie sollten die GA4-Migration daher nicht auf die leichte Schulter nehmen, sie gehört in Experten-Hände. Eine GA4-Migration muss sauber geplant und ebenso sauber umgesetzt werden. Basis für die erfolgreiche technische Umsetzung ist die strategische Planung. Folgende fünf Punkte sollten Sie in Ihrer Strategie unbedingt berücksichtigen, damit der Umstieg problemlos gelingt:
Tipp 1: Nicht abwarten, handeln!
Entwerfen Sie eine Strategie und stellen Sie jetzt die richtigen Weichen für eine gelungene GA4 Migration. Dazu sollten Sie zunächst ihre Erwartungen hinterfragen und ihre Analytics-Ziele definieren: Welche Fragen soll GA4 beantworten, welche Informationen müssen dafür gesammelt werden und wofür sollen diese Informationen genutzt werden? Auf diese Weise wird ersichtlich, welche Daten und Analysen in jedem Fall zu GA4 umgezogen werden müssen. Bei dieser Gelegenheit können Sie gleich überprüfen (oder überprüfen lassen) ob alle benötigten Kennzahlen tatsächlich bereits in Universal Analytics gemessen werden – denn was bisher nicht erhoben wird, kann auch nicht migriert werden. Nutzen Sie die Umstellung also auch als Chance für die Verbesserung Ihrer Messungen! Mitunter kann es sogar sinnvoll sein, die „alten“ Universal Analytics Daten über BigQuery bei Google auszulesen und im eigenen Data Warehouse abzuspeichern. Data Warehouse Experten können Ihnen hier mit weiteren Tipps und Anregungen weiterhelfen, um eine optimale Performance zu erreichen.
Für eine reibungslose Migration sollten Schnittstellen, Ansichten und DSGVO-Anforderungen in der Zielsetzung berücksichtig werden. Informieren Sie sich im Vorfeld auch darüber, welche neuen Möglichkeiten GA4 speziell für ihr Business bietet und nehmen Sie dies als Wunsch an Ihr Implementierungsteam auf. Auch welche KPI gemessen und welche Nutzerinteraktionen erfasst werden sollen, gehören in eine Anforderungsanalyse. Sie wird in der Regel später zusammen mit ihrem Implementierungsteam erarbeitet, aber es ist hilfreich, sich schon frühzeitig damit zu beschäftigen.
Ebenso sollten Sie sich bereits vor der eigentlichen Migration Gedanken über die nötigen Nutzerrollen machen – wer im Unternehmen muss und wer darf Zugriff auf welche Daten haben? Eng damit verknüpft ist die Überlegung, ob durch die angestrebte Rollenverteilung Schulungsbedarf entsteht – und wenn ja, für welche Mitarbeiter.

Tipp 2: Verantwortlichkeiten und Prozesse definieren
Ähnlich wie bei einem klassischen IT-Projekt kommt der Ressourcenplanung bei der GA4-Migration eine Schlüsselrolle zu. Ermitteln Sie, welche Ressourcen für den Migrationsprozess in jedem Fall benötigt werden:
- Sind entsprechende Ressourcen und Know-how intern vorhanden oder benötigen Sie externe Hilfe?
- Wer leitet das Projekt, wer sind Ansprechpartner?
- Können Testszenarien etabliert werden?
- Wie kann im laufenden Betrieb umgestellt werden?
- Bis wann soll der Umstieg abgeschlossen sein? Legen Sie einen detaillierten Zeitrahmen fest.
Damit der Umstieg auch im laufenden Betrieb reibungslos verläuft, sollten Sie Universell Analytics und Google Analytics 4 so lange wie möglich parallel laufen lassen, um Ergebnisse zu vergleichen, feinzujustieren und eine solide Datenbasis in GA4 zu schaffen, bevor UA abgeschaltet wird. Außerdem können Sie im Parallelbetrieb besser nachvollziehen, wie sich Veränderungen in der Datenerhebung und den Metriken im Reporting auswirken.
Tipp 3: Vor Datenverlusten schützen
Voraussichtlich Ende des Jahres 2023 wird der Zugriff auf Universal Analytics Properties komplett gekappt. Daher ist es wichtig, die Berichte zu historischen Daten rechtzeitig zu exportieren. Dies kann in verschiedenen Formaten erfolgen, unter anderem in CSV, PDF, Google Tabellen oder auch Microsoft Excel. Ebenso können Daten mit der Google Analytics Reporting API exportiert werden. Google Analytics 360-Kunden können auch Daten in BigQuery – in das Data Warehouse auf der Google Cloud Platform – exportieren.
Ihre Daten werden aber nicht zwangsläufig von einem System in ein neues übertragen. Vielmehr werden im Regelfall die neuen Daten – mit potenziell gleichen Trackingpunkten – in einem neuen Datentopf erfasst. Um einem Datenverlust schon im Vorfeld vorzubeugen, sollten Sie daher besonderes Augenmerk auf eine akribische Konzeption legen. Sie sollten insbesondere darauf achten, dass keine der bisher relevanten Trackingpunkte beim Umstieg auf GA4 vergessen werden.
Tipp 4: Umsetzen (lassen) und auf Qualität achten
Sind das Know-how und die Ressourcen bei Ihnen inhouse verfügbar, können Sie intern ein Implementierungsteam beauftragen. Sie ersparen sich damit die Dienstleisterkosten. Auf der anderen Seite bietet es sich insbesondere für ein solches Projekt an, auf externe Digital-Experten zurückzugreifen, da diese Dienstleister in der Regel bereits wertvolle Praxiserfahrungen mit der Umstellung anderer Kunden gesammelt haben. Das sorgt für flüssige Prozesse und stellt von vornherein eine hohe Qualität der Migration sicher. Sind Know-how und/oder personelle Ressourcen im eigenen Haus nicht vorhanden, müssen Sie möglichst frühzeitig externe Experten hinzuziehen.
Um die Zusammenarbeit mit dem Implementierungsteam optimal vorzubereiten, sollten Sie Ihre betriebswirtschaftlichen Anforderungen und die benötigten Kennzahlen klar formulieren können. Denken Sie an dieser Stelle auch gern einen Schritt weiter: Müssen noch weitere Daten angebunden werden? Zum Beispiel Google Ads, Google Search Konsole, BigQuery? Und vor allem sollten Sie auch bereits an dieser Stelle die späteren Prozesse in Ihrem Unternehmen im Blick haben: Welche Datenansichten benötigen Sie in Ihrem Bereich, um die richtigen Entscheidungen treffen zu können – loten Sie daher auch die Personalisierungs- und Filtermöglichkeiten des Dashboards aus.
Achten Sie vor allem darauf, dass die Anforderungen an Datenschutz und DSGVO frühzeitig berücksichtigt werden. Dazu ist es beispielsweise auch wichtig zu wissen, welche Cookies von welchem Anbieter wie lange die Daten speichern. Ein ganz besonderes Augenmerk müssen Sie beim Thema Datenschutz auf das Consent Management legen. Ohne Einwilligung der Nutzer dürfen Sie keine Daten zum Nutzerverhalten speichern. Es ist somit sehr hilfreich, sich bereits vor der eigentlichen technischen Migration auf GA4 Gedanken darüber zu machen, wie das Consent-Management stattfinden soll. Sie können zum Beispiel ein Einwilligungsbanner, eine benutzerdefinierte Lösung oder eine Plattform zur Einwilligungsverwaltung (Consent Management Platform, CMP) verwenden. Nicht zuletzt sollten Sie auf eine korrekte Datenschutzerklärung auf der analysierten Website achten.
Tipp 5: Testen, schulen, optimieren
Ist die technische Migration abgeschlossen, sollten Sie ein Feintuning nachschieben. Jetzt gilt es, Berichte und Benutzeroberflächen zu individualisieren, diese immer wieder zu optimieren und – falls nötig – die Mitarbeiter darauf schulen. Dieser Bedarf kann je nach Anforderung und Position unterschiedlich sein, je nachdem ob zum Beispiel Marketing, Sales, C-Level, Webdesigner oder eine andere Rolle im Unternehmen mit den analysierten Daten arbeiten soll. Wichtig ist auch ein kontinuierlicher Qualitätscheck: Funktionieren Verlinkungen und Tracking? Echtzeitberichte geben schnell über Fehler Aufschluss, insbesondere, wenn sie Ergebnisse noch mit der parallellaufenden UA-Version vergleichen können.
Ebenso kann es hilfreich sein, in einem Fragebogen an die Online-Marketing-Stakeholder*innen abzufragen, welche Kennzahlen sie in ihrer Arbeit aus dem Dashboard zurate gezogen haben. Damit lässt sich beispielsweise eine halbjährige Qualitätskontrolle verbinden, indem die Nutzerzufriedenheit abgefragt wird: „Werden die betriebswirtschaftlichen Kennzahlen durch die Metriken so untermauert, dass sie das Arbeiten vereinfachen?“ „Welche Kennzahlen wünschen Sie sich?“ Ein solcher Fragebogen kann gleichzeitig als Grundlage für immer wiederkehrende Optimierungen dienen. Zu guter Letzt sollten Sie die Augen offenhalten und auf Updates achten, um gegebenenfalls neue Funktionen zu implementieren.
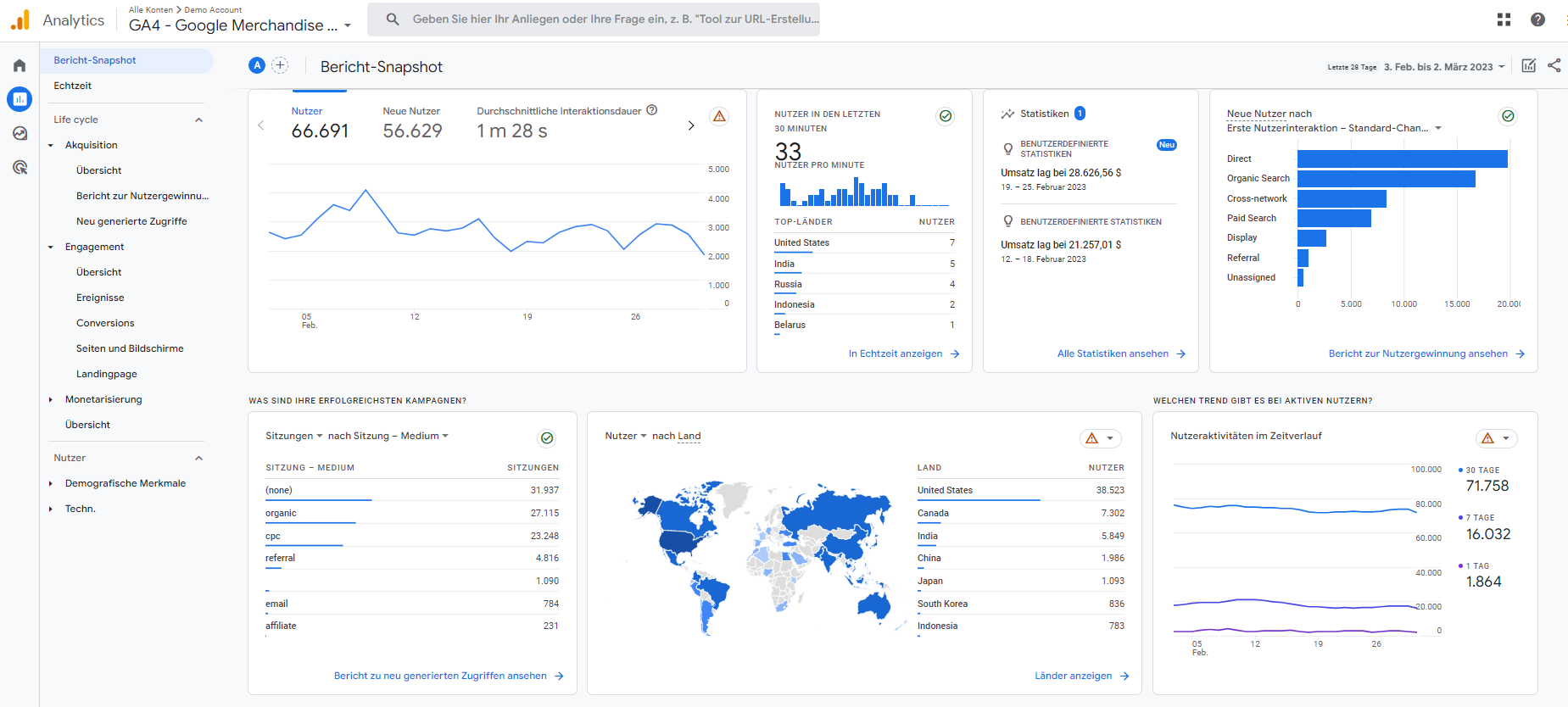
Screenshot eines Google Analytics 4 Demo Accounts.
Fazit und Empfehlung
Es zeigt sich, dass eine erfolgreiche Migration mehr ist als eine reine technische Umsetzung. Doch die Zeit drängt. Abwarten ist in Anbetracht des von Google gesteckten Zeitplanes nicht zu empfehlen. Wenn Sie hingegen die ersten Monate dieses Jahres nutzen, um eine passende Strategie für den Umstieg auf die neue Lösung zu entwickeln, steht einer reibungslosen und pünktlichen GA4-Migration nichts im Weg. Auf den Schutz Ihrer Daten und eine hohe Umsetzungsqualität sollten sie dabei besonderes Augenmerk legen. Lassen Sie sich unkompliziert beraten und bringen Sie Ihre Webanalyse auf den richtigen Weg.
Für die eigentliche technische GA4-Migration empfehlen wir, auf eine standartisierte Lösung zu setzen, bei der Kosten, Umfang und Dauer klar definiert sind. Damit vermeiden Sie unangenehme Überraschungen oder Endlos-Migrationen, wie es bei vergleichbaren IT-Projekten mitunter zu beobachten ist.
Sollten Sie Fragen haben, sprechen Sie uns an. Unsere erfahrenen GA4-Experten beraten Sie gern und übernehmen auf Wunsch auch die komplette Umstellung Ihrer Properties.

Besser entscheiden – 5 Tipps für ein exzellentes Dashboard
Besser entscheiden – 5 Tipps für ein exzellentes Dashboard
Lesedauer: 6 Minuten
Es ist eine Krux: Jeder spricht von datenbasierten Entscheidungen, aber in der Praxis ist das oft schwer umsetzbar. Das Hauptproblem ist, dass Daten häufig in unterschiedlichen Silos abgelegt und nicht ganzheitlich betrachtet werden. Teilweise müssen daher mehrere Systeme bedient werden, um sie einsehen zu können. Single Point of Truth? Fehlanzeige. Von den üblichen Diskrepanzen zwischen verschiedenen Teams und Verantwortungsbereichen ganz zu schweigen. Wenn beispielsweise das Marketing den Umweg über die IT gehen muss, um Website-Daten und Analytics Insights einzusehen, sorgt das dafür, dass beide Teams ausgebremst werden und nicht flexibel arbeiten können. Hinzukommen Fachkräftemangel, enge Budgets und immer mehr Zeitdruck: Es ist heutzutage einfach kein Platz mehr für langsame oder falsche Entscheidungen – und die sollten auf Daten basieren und nicht auf dem Bauchgefühl. So wird es eingefordert. Doch keine Sorge: Sie müssen nicht das gesamte Unternehmen auf den Kopf stellen, um datenbasiert bessere Entscheidungen treffen zu können. Optimierte Dashboards können ein gewaltiger Turbo sein.
Gängige Business Intelligence Tools ermöglichen es, Daten aus unterschiedlichen Silos zentral mit Hilfe von Dashboards zu visualisieren und verbessern die Zusammenarbeit – sowohl im Team als auch abteilungsübergreifend. Außerdem erweitern und präzisieren sie das Reporting. Business Intelligence Tools wie Tableau, Power Bi und Domo sind im Markt weit verbreitet. Auch Google bietet mit Looker Studio (ehemals Google Data Studio) eine eigene BI Lösung an. Solche Tools im Default-Modus zu betreiben, ist ein Schritt in die richtige Richtung. Doch die richtige Power entfaltet ein Dashboard erst, wenn man es optimal auf die Ziele und Bedürfnisse der jeweiligen Nutzer ausrichtet.
Und das ist dringend nötig. Ob Personal, Marketing oder Vertrieb – verschiedene Units haben unterschiedliche Anforderungen. Außerdem besteht die Herausforderung, je nach Szenario und Nutzerrolle die wirklich aussagekräftigen Kennzahlen auszuwählen. Wer sich hier mit dem Standard zufrieden gibt, verschenkt viel Potenzial. Wenn Sie hingegen Dashboards gezielt und anforderungsspezifisch optimieren, können Sie Erfolge genauer messen und somit auch präziser und schneller entscheiden. Schneller entscheiden bedeutet übrigens auch, schneller zu reagieren – und das kann sogar beim Kostensparen helfen, denn Sie sehen sofort, wo Geld verbrannt wird und wo das Budget besser investiert wäre. Im Idealfall gibt das System sogar konkrete Handlungsempfehlungen. In der Praxis zeigt sich immer wieder: Schon kleine Optimierungen am Dashboard können Großes bewirken.
Folgende Tipps helfen Ihnen, aus Ihrem Standard-Tool ein exzellentes Dashboard zu machen:
Tipp 1: Gehen Sie strukturiert und in kleinen Schritten vor
Es ist verlockend, zuerst auf den Datenberg zu schauen und sich dann zu fragen, was man daraus machen könnte. Aber das ist der falsche Ansatz. Stattdessen sollten Sie für Ihre Optimierungen mit konkreten Zielvorgaben arbeiten. Was ist das Ziel und welche Entscheidungen sind dafür nötig – und welche Analysen müssen somit optimiert werden, um dieses Ziel besser zu erreichen? Sind die nötigen Analysen identifiziert, muss sichergestellt sein, dass die für diese Optimierung nötigen Datenquellen vorhanden und nutzbar sind.
Aber Achtung: Nicht mehr Daten sind das Ziel, sondern die richtigen. Zu viele Daten können aussagekräftige Visualisierungen und klare Entscheidungen gleichermaßen erschweren. Schärfen Sie Ihre Ziele und die dafür nötigen Reports, und gehen Sie dabei strukturiert vor. Bedenken Sie, dass Dashboards zielgruppenspezifisch angepasst werden müssen. Operative Nutzer benötigen eher tiefgehende und granulare Daten, Geschäftsführer hingegen eher oberflächlichere Daten. Besonders erfolgversprechend ist ein iteratives Optimieren in kleinen Schritten – Team für Team, Abteilung für Abteilung.
Tipp 2: Optimieren Sie Leistung und Geschwindigkeit
Ein gutes Dashboard muss nicht nur einfach zu bedienen sein, sondern auch optimal performen. Leistung und Geschwindigkeit können mitunter schon mit wenigen Einstellungen gesteigert werden. Zunächst sollten Sie das Reporting und die zugrunde liegenden Messdaten auf den Prüfstand stellen: Welche Kennzahlen müssen wirklich im Report aufgeführt werden? Welche sind wenig zielführend? Insbesondere sollten Sie überprüfen, ob wirklich alle Daten eine Visualisierung benötigen. Wenn Sie hier unnötige Informationen aussieben, können Sie Ladezeiten verringern und Speicherkapazitäten einsparen. Aber Achtung: Dabei ist Fingerspitzengefühl gefragt: Falsche Daten führen zu falschen Schlüssen und somit zu falschen Entscheidungen.
Ein gern genommener Fallstrick ist in diesem Zusammenhang, keine Kennzahlen zu betrachten, sondern lediglich viele Messwerte. Doch erst Kennzahlen können Zustände und Vorgänge quantifizieren, da sie Messwerte in Bezug zu anderen Daten oder Prozessen setzen. Für eine Entscheidungsfindung sind insbesondere die KPI (Key Performance Indicators) relevant – also entscheidende Kennzahlen, welche die kritischen Erfolgsfaktoren widerspiegeln, die für eine bestimmte Zielsetzung nötig sind. Management Dashboards sollten sich auf diese beschränken. Idealerweise gibt es im Unternehmen bereits ein einheitliches Verständnis, mit welchem Dashboard KPI welches Ziel gemessen wird. Falls nicht, sollte ein KPI Framework der Dashboard-Optimierung voraus gehen.

Photo by Stephen Dawson on Unsplash
Tipp 3: Visualisieren Sie effizienter und aussagekräftiger
Um aussagekräftige Visualisierungen auf das Dashboard zu zaubern, sollten Sie mit Ebenen und Hierarchien arbeiten. Über clevere Drill-Down-Menüs können Sie ausgehend von einer Gesamtansicht dann detaillierte Einblicke erhalten, indem Sie – oder Ihre Teammitglieder – sich in Ergebnisse „hineinzoomen“. Generell hat sich für den Aufbau der Visualisierungen die „2-20-200“-Regel bewährt: In den ersten zwei Sekunden muss sich beim Blick auf ein Dashboard die Gesamtsituation erschließen. Läuft es gut oder besteht Handlungsbedarf? In den folgenden 20 Sekunden hat man Gelegenheit, genauer hinzuschauen: Welche Entwicklungen sind für das Gesamtbild verantwortlich? Anschließend geht es in einen 200-Sekunden-Deep-Dive, in dem man den Ursachen im wahrsten Sinne des Wortes auf den Grund gehen kann. Mit gezielten Abfragen und Filtern lässt sich nun nach den Gründen der aktuellen Entwicklung forschen.
Um aussagekräftig zu visualisieren, ist es außerdem wichtig, die Ergebnisse in einen Kontext zu setzen. Wie ist diese Grafik zu bewerten? Etablieren Sie daher Vergleiche – zu einem früheren Zeitraum, einem gesteckten Ziel oder einem branchenüblichen Benchmark. Passende Diagrammtypen und eine deutlich unterscheidbare Farbgestaltung sollten dabei selbstverständlich sein. Potenzielle Probleme oder Anomalien sollten Sie automatisch sichtbar machen, beispielsweise indem Sie automatisierte Warnhinweise anlegen, beziehungsweise überdurchschnittliche oder unterdurchschnittliche Ergebnisse automatisch hervorheben lassen. Kommentarfunktionen können helfen, um im Team Ergebnisse schneller richtig zu interpretieren.
Tipp 4: Kreieren Sie Auswertungen, die motivieren und Leistungsanreize schaffen
Controlling war gestern, Teamgeist ist heute: Ein Dashboard sollte den Teamgeist unterstützen. Wenn Dashboards von mehreren Personen genutzt werden, ist es umso wichtiger, dass die Auswertungen allgemein verständlich und möglichst auf einen Blick erfassbar sind. Hier ist es ratsam, zu den aktuellen Auswertungen passende Vergleiche oder Kontexte bereitzustellen, die auf das Team motivierend wirken.
Ebenso sollten Sie Ihr Team mit den Zahlen und Diagrammen nicht allein lassen, sondern „an die Hand nehmen“ – am besten mit konkreten Handlungsempfehlungen. Zum Beispiel kann es sinnvoll sein, für KPI Schwellenwerte zu definieren, um Abstufungen zu visualisieren und nicht sofort „Alarm auszulösen“. Für solche abgestuften Anzeigen lassen sich im Vorfeld ebenfalls entsprechende Handlungsempfehlungen definieren, die dann automatisiert ausgespielt werden.
Tipp 5: Automatisieren Sie Datenströme und achten Sie auf Flexibilität
Die ultimative Performance-Stufe zünden Sie mit cloudbasierten Dashboards und automatisierten Datenströmen. Damit bleiben Sie quasi in Echtzeit up-to-date. Die Datensammlung erfolgt vollautomatisch über entsprechende APIs, gespeichert werden die Daten in einem zentralen Data Lake. Um Reports und Dashboards weiter zu personalisieren, lassen sich weitere Tools problemlos einbinden. Das initiale technische Setup sollten erfahrene Data Engineering Experten für Sie übernehmen, die anschließende Handhabung ist wie gewohnt bequem in Eigenregie möglich.
Auf diese Weise automatisierte Dashboards sorgen für beträchtliche Zeitersparnisse und benötigen weniger Man-Power – in Zeiten des Fachkräftemangels kein unerheblicher Aspekt. Auch die Fehlerquote wird damit auf ein Minimum reduziert. Auf wechselnde Anforderungen können Sie mit automatisierten Dashboards besonders gut reagieren, egal ob sich zum Beispiel Datenströme ändern oder Zeitintervalle angepasst werden sollen. Weitere Informationen zum Ablauf der Anbindung, sowie der Funktionsweise der cloudbasierten Dashboard-Automatisierung, finden Sie in diesem Blog-Beitrag.
Übrigens: Eine exzellente Reporting-Struktur aufzuziehen ist nicht einfach. Und selbst wenn diese bereits aufgebaut wurde, ist die Entwicklung nie ganz abgeschlossen. Daher ist es wichtig, eine Dashboard-Optimierung auch kontinuierlich im Blick zu haben. Welche Auswertungen wurden im vergangenen Zeitraum wirklich genutzt? Welche Datenquellen sind jetzt neu verfügbar? Wo fehlen noch Informationen? Wenn Sie in regelmäßigen Abständen – zum Beispiel alle sechs Monate – genutzte Datenquellen, Informationen und Schnittstellen mit Ihren aktuellen Zielsetzungen abgleichen, haben Sie gute Chancen, jederzeit mit Hilfe eines exzellenten Dashboards bessere Entscheidungen zu treffen. Gleichzeitig etablieren Sie damit einen nachhaltigen Prozess, mit dem Sie Optimierungspotenziale zu jedem Zeitpunkt auf einen Blick erkennen.
Photo by Luke Chesser on Unsplash
Fazit und Empfehlung
Eine exzellente Reporting-Struktur aufzuziehen ist nicht einfach. Und selbst wenn diese bereits aufgebaut wurde, ist die Entwicklung nie ganz abgeschlossen. Daher ist es wichtig, eine Dashboard-Optimierung auch kontinuierlich im Blick zu haben. Welche Auswertungen wurden im vergangenen Zeitraum wirklich genutzt? Welche Datenquellen sind jetzt neu verfügbar? Wo fehlen noch Informationen? Wenn Sie in regelmäßigen Abständen – zum Beispiel alle sechs Monate – genutzte Datenquellen, Informationen und Schnittstellen mit Ihren aktuellen Zielsetzungen abgleichen, haben Sie gute Chancen, jederzeit mit Hilfe eines exzellenten Dashboards bessere Entscheidungen zu treffen. Gleichzeitig etablieren Sie damit einen nachhaltigen Prozess, mit dem Sie Optimierungspotenziale zu jedem Zeitpunkt auf einen Blick erkennen.

Cem Alkan zu Gast beim Podcast 121Stunden Talk
Mach deine Webanalyse fit für 2023
Das Ende des Jahres rückt näher, wann lässt es sich besser in die unmittelbare Zukunft schauen, als zu diesem Zeitpunkt? Unser Head of Academy Cem Alkan war in dieser Woche zu Gast im 121Stunden Talk von 121Watt und hat die Analytics Trends für 2023 beleuchtet.
Cem nennt den Hauptgrund, warum ein Großteil der Web-Analyse Projekte bereits zu Beginn zum Scheitern verurteilt sind und wie man dagegen vorgehen kann. Die Bedeutung der Data Literacy (Datenkompetenz) wird aufgezeigt und warum jedes Unternehmen diese aufbauen muss. Selbstverständlich wird über das Thema Cookieless Tracking gesprochen und wie Server Side Tracking einen möglichen Ansatz für Cookieless Tracking darstellt.
Cem beschreibt zudem, warum Web-Analyse Projekte wie IT-Projekte behandelt werden sollten, um die nötige Kontrolle über diese zu behalten und im Zweifel auf veränderte Anforderungen reagieren zu können. Zu guter Letzt wird der Fokus auf das Generieren von Insights gelegt.
Happy Analyzing!
121Stunden Talk Folge 81
(Quelle: 121Watt)
Den Podcast finden Sie überall, wo es Podcasts gibt. Die üblichen Player haben wir hier verlinkt:
Sie haben Rückfragen zu den im Podcast angesprochenen Themen? Gerne beantworten wir diese. Sie erreichen uns ganz einfach über das Kontaktformular oder telefonisch unter 040 35085425.

Vor- und Nachteile von Server Side Tracking
Vor- und Nachteile von Server Side Tracking
Lesedauer: 5 Minuten
Aktuelle Marktsituation
Sie haben sicherlich schon davon gehört: Aufgrund der DSGVO-Bestrebungen ist das Thema Datenschutz in aller Munde. Auf Basis von den Regelungen der DSGVO werden immer mehr Rechtsurteile gesprochen und Strafen verteilt. Den Marketingabteilungen wird das Tracking der Nutzer auf den eigenen Websites oder in den eigenen Apps erschwert, das Thema “Datenschutz” durchdringt viele Abteilungen eines Unternehmens.
Die resultierenden Bedenken im Rahmen des Trackings der Nutzer auf den Websites und Apps ist verständlich und auch richtig. Die Gunst der Stunde kann Server Side Tracking nutzen. Server Side Tracking kann im Rahmen des Trackings als Baustein gesehen werden, um den schärfer werdenden Datenschutzanforderungen gerecht zu werden, alleine wird es diese Anforderungen aber nicht lösen.
Wir möchten in diesem Blogbeitrag allerdings nicht die Bedenken oder gar das Thema Datenschutz behandeln, sondern zeigen einen Weg auf, wie mit Server Side Tracking umgegangen werden kann.
Was ist Server Side Tracking?
Mit Server Side Tracking ist der Einsatz eines eigenen Trackingservers gemeint. Der Trackingserver wird als Zwischeninstanz implementiert, um Nutzerinteraktionen auf der eigenen Website oder App mit Analyse- und Marketingtools zu teilen.
Das Server Side Tracking als eher neue Bewegung am Markt grenzt sich hierbei deutlich vom bisherigen Vorgehen ab, dem Client Side Tracking. Beim Client Side Tracking wird die Nutzerinteraktion auf der Website oder App direkt aus dem Browser des Nutzers bzw. der nativen Applikation an die Analyse- und Marketingtools gesendet. Im Folgenden gehen wir auf die Funktionsweise der Server Side Trackings ein und behandeln die Vor- und Nachteile.
Wie funktioniert Server Side Tracking?
Die Funktionsweise haben wir im vorigen Abschnitt kurz angerissen und vertiefen es hier anhand des Beispiels mit dem Server Side Tracking mit Google Tag Manager.

Request
Geben User in der URL-Zeile ihres Browsers eine Webadresse ein, sendet der Browser eine HTTP-Anfrage an den Server des Website-Inhabers. Somit fragt ein Client Informationen beim Server an und erwartet eine entsprechende Antwort in Form des HTML-Gerüsts, der CSS-Dateien für das Aussehen der Seite und verschiedener Skripte.
Mit anderen Worten: Mit der Adresseingabe in der URL-Zeile fragt der Browser beim Server an, die angefragte Webseite anzeigen zu können.
Response
Sobald der Server das Signal vom Client bzw. Browser erhält, interpretiert er es und sendet seine Antwort. Dazu gehören neben HTML-Gerüst und CSS vor allem JavaScript-Skripte, die unter anderem zum Ausführen von Tracking benötigt werden.
Das heißt, der Server stellt die Informationen bereit, die es braucht, um die Seite im Browser darzustellen.
Tag Manager lädt
Eines dieser Skripte ist beispielsweise der Google Tag Manager (gtm.js), der auf der Seite eingebaut ist. Das ist der client-seitige Container, der vom Google Tag Manager (Website Google Tag Manager) angefordert wird.
Sende Tags
Darin befinden sich anbieter-spezifische Tags, die regalbasiert die erfassten User-Interaktionen auf der Website weiterleiten. Die Besonderheit im Server Side Tracking ist, dass sie jedoch nicht an die jeweiligen Anbieter direkt gesendet werden, sondern an einen eigens eingerichteten Trackingserver. Auf dem Trackingserver ist das Pendant zum Client-Side Tag Manager implementiert, der Server Side Tag Manager.
Datenstrom
Die erfassten und strukturierten Daten auf der Website werden an den Server Side Endpunkt weitergeleitet. Anstatt direkt aus dem Browser die erfassten Daten durch den Tag Manager direkt an die verschiedenen Anbieter zu senden, werden die Daten an den Server Side Tag Manager weitergeleitet. Dies passiert mit jeder zu erfassenden Nutzerinteraktion.
Client
Im Server Side Tag Manager werden die eingehenden Datenströme verarbeitet. Hier gibt es zusätzlich zu den bekannten Tag Manager Funktionen anbieter-spezifische Clients. Diese Skripte warten auf einen Request, der an sie adressiert ist. Sie verarbeiten die eingehenden Informationen zu einem Datenmodell, mit welchem im Server Side Tag Manager gearbeitet wird.
Tags
Basierend auf den eingehenden Datenströmen werden Tags erstellt. Dabei können Daten extrapoliert werden, um Datenhoheit und -qualität zu gewährleisten.
Server Side Tracking Request
Im letzten Schritt wird der neu strukturierte Tag (Request) an das jeweilige Analyse- oder Marketingtool geschickt. Dieser Vorgang ist aus dem Client Side Tracking bekannt. Damit erhalten die Empfänger-Technologien nur noch die Informationen, die ihnen zur Verfügung gestellt werden.
Welchen Nutzen kann ich daraus ziehen?
Durch Server Side Tracking haben Sie gegenüber dem Client Side Tracking Vorteile bezüglich Datenkontrolle, Datenqualität und teilweise in der Websitegeschwindgkeit.
Datenkontrolle / Datenhoheit
Beim Client Side Tracking übernimmt meist ein JavaScript-Skript das Versenden der Daten. Dies geschieht vollautomatisch, was selbstverständlich sehr bequem für das Unternehmen ist.
Beim Server Side Tracking können Sie die Daten im Tag manipulieren. Sie haben die Möglichkeit, gewisse Datenpunkte zu entfernen. Dies könnten z.B. die IP Adresse oder der User Client sein. Durch die volle Kontrolle der versendeten Datenpunkte adressiert das Server Side Tracking hervorragend etwaige bestehende Bedenken hinsichtlich der Data Governance Thematik und Sie gewinnen die Hoheit über Ihre Daten zurück.
Datenqualität trotz AdBlocker & Tracking Prevention
Der nächste Aspekt, den wir aufzeigen werden, ist die Erhöhung Ihrer Datenqualität durch die Umgehung von AdBlockers oder Tracking Prevention Maßnahmen einiger Browseranbieter (Apple Safari, Mozilla Firefox).
Die in der Vergangenheit zugenommenen Werbeausspielungen und Trackings im Internet führten dazu, dass viele Nutzer und einige Browserhersteller Maßnahmen eingeleitet haben, um den Nutzer zu schützen. Die Maßnahmen blockieren Trackings, weswegen die Qualität der Daten in den einzelnen genannten Tools (z.B. Web Analyse oder Online Marketing) abnehmen kann.
Da beim Server Side Tracking die Requests nicht direkt an die Anbieter gesendet werden, sondern an die eigene Subdomain, werden diese Browser-seitigen Maßnahmen zur Trackingprevention umgangen, was zur Erhöhung der Datenqualität führt.
Erhöhung der Websitegeschwindigkeit
Durch die Verlagerung des Tracking aus dem Client Side Tracking zum Server Side Tracking wird der Payload reduziert. Unter Payload versteht man u. a. die Datenmenge, die bei der Kommunikation im Internet hin- und hergeschickt wird.
Die Höhe des möglichen Einsparungspotenzials hängt im Einzelnen von den exisitierenden Track Trackings ab, die aus dem Client Side Tracking in das Server Side Tracking umgelagert werden.
Welche Nachteile sind mit Server Side Tracking verbunden?
Der Einsatz vom Server Side Tracking bringt nicht nur Vorteile mit sich, sondern ist ebenfalls mit Nachteilen verbunden. Die berühmte Kehrseite der Medaille ist in diesem Fall eine steigende Komplexität, verbundene Kosten und das relativ frühe Stadium in der Massentauglichkeit.
Komplexität
Wie Sie sicherlich schon aus dem Blogartikel entnommen haben, steigt mit der Implementierung eines Server Side Trackings auch die Komplexität Ihrer generellen Tracking-Implementierung. Technisches Fachwissen und Expertise zum Aufsetzen eines Tracking Servers und zum Umgang mit dem Server Side Tag Manager sind dringend von nöten.
Durch die Umsetzung eines sauberen Server Side Tracking Setups ist die laufende Instandhaltung hinsichtlich ihrer Komplexität einem bestehenden Client Side Tracking Setups gleichzusetzen.
Kosten
Anders als beim kostenlosen Client Side Tracking mit GTM fallen beim Server Side Tracking Kosten für den Server mit dem Google Tag Manager GTM Container an. Dieser lässt sich sowohl in Cloud Umgebung von entsprechenden Anbietern als auch in einer eigenen Cloud umsetzen und betreiben. Für ein einfaches Setup bietet sich hierzu aktuell die Google Cloud an.
Die entstehenden Kosten setzen sich dabei aus monatlichen Kosten für die benötigten Server (CPU, Speicherplatz, etc.) und Kosten basierend auf den Zugriffen auf der Website / App. Die folgenden beispielhaft errechneten Kosten beziehen sich auf die Nutzung der Google Cloud App Engine.
Pro Server fallen Kosten in Höhe von ca. 40 Euro an, wobei Google den Einsatz von mindestens drei Servern empfiehlt, um Datenverluste zu vermeiden. Folglich sollten für die Server Kosten in Höhe von ca. 120 Euro eingeplant werden. Die Anzahl der benötigten Server steigt, je stärker eine Seite besucht und genutzt wird. Dazu kommen die Nutzungskosten, die über ein flexibles Abrechnungsmodell abgerechnet werden und deren Höhe sich aus der Intensität der Nutzung und Auslastung der Server (Stichwort „Traffic“) ergibt.
Sie können mit Kosten pro Server mit ca. 40 EUR rechnen und weiteren ca. 100 EUR pro 500.000 Requests auf den Server.
Massentauglichkeit
Das Server Side Tracking ist technisch einwandfrei umsetzbar, befindet sich allerdings hinsichtlich der Anzahl unterschiedlicher Anbieter, die serverseitig Daten empfangen können, noch in der early-adopter Phase. Mit fortschreitender Zeit werden immer mehr Anbieter die Möglichkeit schaffen, serverseitig Daten zu empfangen und somit einen weitern Grund liefern, das Server Side Tracking einzusetzen.
Unser Schlusswort
Das Server Side Tracking ist eine zukunftsfähige Technogie, deren Einsatz mit zunehmender Massentauglichkeit sicherlich auch Einzug in die meisten Tracking-Implementierungen halten wird. Die positiven Aspekte, gerade im Rahmen der Data Governance und der Datenqualität, werden die Aspekte Komplexität und Kosten mehr als aufwiegen.
Wenn Sie schon heute zukunftsorientierte Trackinglösungen in Ihrem Unternehmen einsetzen wollen, lassen Sie sich von den Experten der Digital Motion hierzu beraten. Wir nehmen Ihnen die komplexe Implementierung ab und helfen Ihnen, das benötigte Know-How aufzubauen. Unser Produkt “Server Side Tracking (Google)” wurde eigens für die Umsetzung entwickelt.
Für mehr Informationen zum Server Side Tracking (Google) klicken Sie hier.